|
|
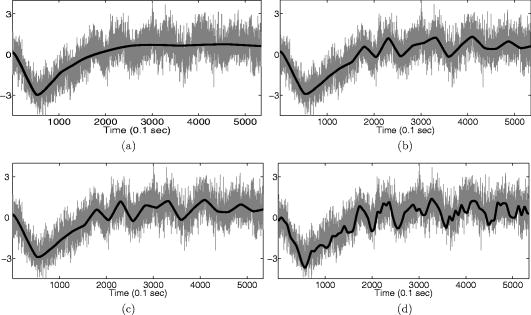
1.IntroductionNear-infrared (NIR) light, with a wavelength between and , is capable of penetrating deeply through biological tissues. This is because NIR light is weakly absorbed by biological chromophores such as hemoglobin, myoglobin, and cytochrome c oxidase.1 The relatively deep penetration depth of NIR light in the human brain makes it possible to measure brain activities associated with regional changes of oxy- and deoxy hemoglobin concentrations.2 This spectroscopic technique using NIR light for monitoring brain activities is known as functional near-infrared spectroscopy (NIRS).3 NIRS is regarded as a promising neuroimaging modality owing to a number of advantages over other neuroimaging modalities such as positron emission tomography (PET) and functional magnetic resonance imaging (fMRI).3 For example, there is no theoretical limitation on temporal resolution (while of course there are practical limits arising from, for example, the speed of the analog-to-digital converter). The temporal resolution of NIRS, therefore, is sufficient to investigate hemodynamic responses due to brain activations as well as other fast varying physiological conditions. Furthermore, NIRS does not require that the subject lie on his/her back in a confined environment during experiments, thereby making it possible to investigate subjects that would normally be difficult to examine using fMRI or PET, including infants, children, and patients with psychological issues. Moreover, NIRS is highly flexible, portable, and relatively low cost. However, there remain several theoretical and practical difficulties for quantitative analysis of NIRS data. For example, the differential path length factor (DPF)4 depends on various parameters such as the age of the subject,5 wavelength of the imaging system,6 and position within a brain.7 Time-resolved or frequency domain NIRS equipment may be used to estimate the mean optical path length; however, continuous wave (CW) systems are more commonly used due to several practical concerns such as cost of implementation.7 Other subject-dependent parameters such as depth of the skull and optical properties of hair may influence measurement of optical parameters. Recently, many researchers have been developing statistical analysis toolboxes for NIRS based on the generalized linear model (GLM).8, 9, 10, 11 The GLM is a statistical linear model that explains data as a linear combination of explanatory variables plus an error term. Since the GLM analysis relies on the temporal variational pattern of signals, it is more robust to differential path length factor (DPF) variation, optical scattering, or poor contact. Furthermore, statistical parameter mapping (SPM) using the GLM is a standard method for analyzing fMRI data,12 and thus integration of NIRS and fMRI within the same SPM framework may offer the advantage of modeling both types of data in the same mathematical framework to make inferences. Based on these observations, we have developed a new public domain statistical toolbox called NIRS-SPM.11 By incorporating the GLM with the -value calculation using Sun’s tube formula,13, 14 NIRS-SPM not only enables calculation of activation maps of oxy-, deoxy, and total hemoglobin but also allows for super resolution localization, which is not possible using conventional analysis tools.11 Note that the GLM often fails when there exist global drifts in the NIRS measurements due to various reasons, such as subject movement, blood pressure variation, and instrumental instability. This global trend causes a low-frequency bias in NIRS measurements. Moreover, the amplitude of the global drift is often comparable to that of the signal from brain activation, which degrades the signal-to-noise ratio. In order to eliminate the global trend and thus improve the signal-to-noise ratio, high-pass filtering is often used in practice.15 However, the signals from brain activations are often degraded by a simple filtering, since the frequency response of the hemodynamic response can also be affected during high-pass filtering. In order to overcome this problem, this paper investigates a wavelet-based detrending algorithm for fMRI16 and adapts it for NIRS applications. Specifically, the wavelet transform was applied to decompose NIRS measurements into global trends, hemodynamic signals, and noise components at distinct scales. However, unlike fMRI data, the NIRS time series is considerably long due to the fast sampling frequency. Hence, we observed that direct application of the model order selection rule in Ref. 16 leads to erroneous results in NIRS. To remedy this problem, the minimum description length (MDL) principle with universal prior of integers17 is found to be suitable for the NIRS time series, as it avoids over- and underfitting of the global trend estimate, thanks to the asymptotic optimality of MDL. Experimental results confirm that the new detrending algorithm outperforms the conventional approaches. We have therefore incorporated the proposed Wavelet-MDL detrending algorithms within our NIRS-SPM framework, which will soon be publicly available at the website of the authors (http://bisp.kaist.ac.kr/NIRS-SPM). We observed that the Wavelet-MDL detrending method within NIRS-SPM provides more specific localizations of the neuronal activation than the standard high-pass filtering approach based on the discrete cosine transform (DCT). 2.NIRS Measurement ModelThe modified Beer-Lambert law (MBLL), which describes optical attenuation in a highly scattering medium such as biological tissue,4 provides a relation between raw optical density (OD) data and changes of chromophore concentrations. According to the MBLL, the change in for the wavelength at the cerebral cortex position at time due to the number of chromophore concentration changes is described as where denotes the final measured optical intensity, denotes the initial measured optical intensity, is the extinction coefficient of the ’th chromophore at wavelength , is the DPF, and is the distance between the source and detector at position , respectively. Assuming that oxy- and deoxyhemoglobin are the major two choromophores, the noisy measured optical density is then described by the following matrix formulation:where and denote the time series of the chromophore changes for the oxy- and deoxyhemoglobin, and is the additive noise for the wavelength , respectively. Here, we assume that is the same at both wavelengths and the equality assumption does not affect the validity or applicability of what follows. Then, by multiplying the inverse matrix of the extinction coefficients with Eq. 2, we can derive the expression of the noisy oxy- and deoxyhemoglobin signals:where and is the additive zero mean Gaussian noise for the oxy- and deoxy- channels, respectively. Although the DPF parameter can be measured using time-domain or frequency-domain systems by calculating the temporal point spread function,7 this information is not obtainable in commonly available CW systems. Furthermore, NIRS data acquisition is considerably affected by a variety of measurement conditions, such as the color of hair and the scalp depth, which introduces position- and subject-dependent scattering effects. For these reasons, analyzing NIRS data using the magnitude of chromophore concentration changes is often problematic.3.General Linear Model for NIRSIn the fMRI domain, the validity of the GLM has been extensively tested, and the GLM has been established as a standard analyzing method. Statistical parametric mapping (SPM)18 and analysis of functional neuro images (AFNI)19 are widely used programs based on the GLM. Analysis based on the GLM consists of three steps: model specification, parameter estimation, and statistical inference.15 In this section, we review the GLM approach for NIRS applications.11 The GLM describes a measurement (i.e., or ) in terms of a linear combination of explanatory variables plus an error term: Here, denotes an unknown strength of response, and is an explanatory variable originating from a model of hemodynamic responses. Now, let and denote the vector of the time series of the hemodynamic signal and noise at the location , respectively: The corresponding GLM model in a matrix form is then given by:where is an -dimensional column vector whose elements are the sampled NIRS data at time points, denotes an error vector, and is an -dimensional column vector that represents unknown strengths of the response. Usually, the matrix is called a design matrix and serves as a predictor for the measured signal.15For fMRI signals, Boynton showed that the BOLD signal can be approximated as a convolution model between a stimulus function and a hemodynamic response function (HRF).20 Based on a similar argument, several statistical analysis toolboxes using the GLM are currently available for NIRS.8, 9, 10, 11 The stick function or the boxcar function is typically used for the stimulus function. For the HRF, there are a number of possible models. In this paper, we follow fMRI approaches and employ the so-called canonical HRF, which is composed of two gamma functions.15 Additionally, the derivatives of the HRF with respect to delay and dispersion can be used to mitigate the problem that the precise shape of the HRF varies across the brain.21 An adaptive estimation of HRF using multiple gamma functions can also be used in NIRS to account for oxygen species–dependent hemodynamics variation.11 After the model specification, the least-squares parameter estimator is derived using the ordinary least squares. If the design matrix is of full rank, the least-squares estimate is: where denotes the pseudo-inverse of . With the obtained least-squares estimates, one can construct statistics for the statistical inference. In most cases, we consider a linear combination of the parameter estimates:where the vector is called a contrast vector.15 Similar to the fMRI-SPM analysis,15 the error in Eq. 7 is assumed to be normally distributed with a temporal covariance matrix ; hence, we haveThus, -statistics for the null hypothesis that asserts no activation is given bywhere denotes a random variable with a Student’s -distribution with degree of freedom given as follows:15 where denotes the identity matrix.The estimate of the temporal correlation matrix hence affects the overall -value and corresponding inferences. For a detailed discussion on the estimation of , readers can refer to our previous work on this issue.11 If the calculated -value is larger than a certain threshold value, then the inference steps abandon the null hypothesis and we declare the area to be activated. The threshold value is calculated by fixing a -value in the range of 0.001 to 0.05. A smaller -value provides a higher threshold value. The nonlinear relationship between the -value and threshold can be explicitly represented using the tube formula, as described in our companion paper.11 4.Wavelet-MDL DetrendingIn this section, we develop a novel detrending algorithm that is designed to address the global-drift issues described in the Introduction. Our point of departure is an algorithm developed for detrending the fMRI time series.16 4.1.NotationWe first introduce the notation associated with a discrete wavelet transform by following the standard conventions.22 Let denote a wavelet associated with the multiresolution analysis.22 Let , , and be the scaling function, the low-pass filter, and the high-pass filter associated with this wavelet transform, respectively. With a slight abuse of notation, let be a discrete version of a continuous signal . For simplicity, we assume , where is the maximum level of wavelet decomposition. The wavelet coefficients composed of approximation coefficients and detail coefficients are defined by the following recursions:22 where . We introduce a matrix to represent the discrete wavelet transform:where each submatrix is given by4.2.Modified GLM with Baseline DriftIn the wavelet detrending algorithm for fMRI,16 the baseline drift is included as part of the GLM: where indicates the measured BOLD signal, and denote the predictor and the additive noise with the temporal covariance matrix , and is the additional global drift, respectively. A similar argument may be applied to the NIRS case. We introduce trend terms in Eq. 2 as follows:where denotes the global trend for wavelength at the location . If we multiply the inverse matrix of the extinction coefficients, the equation of the noisy oxy- and deoxyhemoglobin is given aswhere , , and . Let , , and denote vectors of the hemodynamic signal, additive noise, and global trend signal, respectively. If we introduce the GLM for each chromophore, we can derive the modified GLM for NIRS as follows:For simplicity, we remove the subscript from Eq. 17 and use the general form given by Eq. 14.The global trend signal varies smoothly in most cases. Based on this observation, conventional detrending algorithms use filtering to remove the low-frequency trend signal. The problem of this approach, however, is that the hemodynamic signal often has a low-frequency varying component that can be erroneously removed during the filtering. In order to deal with this artifact, in our wavelet detrending, the unknown trend is modeled as a signal restricted in a subspace spanned by coarse scale wavelets.16 More specifically, the trend is modeled as:16 where , , , , , and are defined as earlier, and denotes the finest scale that determines the smoothness of the trend. Note that the detail coefficients are all zero for fine scales, i.e., .Using the discrete wavelet transform (DWT) matrix defined in Eq. 13, we can represent the wavelet transform of a global trend signal as follows: The maximum likelihood estimates for the trend and the unknown signal strength in Eq. 14 are then given by:16 where , andwhere denotes the number of nonzero coefficients that describe the trend, denotes a identity matrix, denotes a matrix whose elements are zero, is a matrix, denotes the noise covariance matrix, is the DWT matrix, and is the ’th wavelet coefficient of the ’th column of design matrix, respectively.Note that in Eq. 20 is the covariance matrix of noise in wavelet domain. Even if the original time series is highly correlated, the array of wavelet coefficients exhibits much less correlation.23 This decorrelating (or whitening) feature of the wavelet transform has been studied in Refs. 23, 24, 25. Especially for the fractional Brownian motion (fBM) process,26 which is a popular model for -type noise, the decay rate of the correlation of wavelet coefficients in ’th scale is derived as:24 where is an expectation operator, is a constant that defines the degree of correlation, and denotes the number of vanishing moments of a wavelet transform. Therefore, for a wavelet transform that has a large enough , we may assume that the noise in wavelet coefficients has the uncorrelated Gaussian distribution whose covariance matrix is given as:where is the variance in the ’th decomposition level. To estimate , we use the median absolute deviation of wavelet coefficients:23, 27 where the number 0.6745 is the calibration factor for Gaussian distribution.23, 27In the wavelet detrending method for a fMRI time series,16 the complexity of the unknown global bias is solely determined by . In other words, there is an implicit assumption that all coefficients at the same scale are all zero or all nonzero simultaneously. However, in the case of NIRS, the number of data points is much larger than that of the fMRI time series, and thus this simple scheme may cause over- or underfitting. Therefore, for a fine-tuned estimate of model order, the wavelet coefficients at the same scale are sorted in order of descending magnitude and are included one by one until a suitable complexity is found by the model order selection criterion. Note that this procedure is similar to MDL thresholding in signal restoration.28, 29 The wavelet detrending method has several advantages over the conventional filtering approach. Note that the conventional filtering cannot prevent the removal of the hemodynamic signal, since it decides the cutoff frequency using only the paradigm repetition frequency, and the nonnegligible amount of the hemodynamic signals can often be filtered out. This is especially true for the event-related paradigm30 since it does not have a well-defined cutoff frequency. Compared with the conventional method, the wavelet-based detrending algorithm includes the design matrix in the least-squares estimation process described in Eq. 20. Hence, the canonical hemodynamics time series is fully utilized in the estimation process, and the algorithm is more robust. Furthermore, the wavelet-based approach is more effective in removing relatively fast varying trends thanks to the optimality of wavelet transform in describing the transient changes of fast varying signals.22 4.3.Minimum Description Length Principle for Model Order SelectionIn Eq. 20, we have shown a simple one-step method for simultaneous estimation of the global trend and the signal strength for a given hyperparameter in terms of maximum likelihood estimation. The remaining issue is the determination of the hyperparameter . Even though is a single integer valued parameter, it affects the whole behavior of the estimated trend signal, since determines the number of wavelet coefficients that describe the trend. More specifically, if is an inappropriately large number, the hemodynamic response is distorted due to the overfitted trend estimate, whereas a smaller value may not capture the unknown trend properly. Therefore, the accuracy of the order estimate (or ) ultimately determines the quality of the trend estimation. The problem of estimating the order (or ) is formally called the model order selection problem.17, 31, 32 A good model order selection criterion should satisfy two conflicting goals simultaneously: goodness of fit and concision of the model. Balancing these two goals is crucial in preventing the over- or underfitting. Akaike information criterion (AIC),33 Schwartz information criterion (SIC),32 and minimum description length (MDL) suggested by Rissanen17 are the most popular criteria currently available. The best model is then selected as the one that gives the smallest cost among several plausible models. These three methods assume that the probability density function (pdf) is a function of unknown model order . Thus, the distance between the true pdf and the estimated pdf induced from the parameter estimate plays an important role. More specifically, AIC and SIC are closely related to the Kullback-Leibler (K-L) distance,34 defined as follows: where stands for the expectation with respect to , denotes a true pdf for data vector , and denotes an approximated pdf governed by the model order , respectively. The K-L distance can serve as a measure of the difference between the true pdf and an estimated pdf. The K-L distance gives a nonnegative value in general, but zero if and only if . The basic concept of AIC and SIC is to minimize the K-L distance. However, it is not trivial to evaluate the K-L distance directly, since it is hard to define the true pdf and . Therefore, asymptotic approximations for the K-L distance have been derived. For example, AIC uses a cross-validation perspective, and SIC employs a prior pdf for the model order (Refs. 35). An improved version of AIC that reduces the probability of overfitting is also available,31 and denoted by . In many cases, outperforms the conventional AIC.35 The and SIC cost functions for detrending are then summarized as:where denotes the log-likelihood of under the model order . The first term can be easily computed under an assumption that the noise is uncorrelated, independent, and normally distributed:where denotes the unknown noise variance. Using the partial derivative of Eq. 26 with respect to , the maximum likelihood estimate of the unknown noise variance is given aswhere we explicitly represent the dependency of on the parameter . Substituting Eq. 27 into Eq. 26, we getwhere const stands for a term that is not related to the model selection problem. Then, by substituting Eq. 28 into Eq. 25, we can find the optimal model order that minimizes the cost functions and SIC, respectively.The MDL principle follows a different philosophy compared with AIC and SIC. Formally, it is based on the Kolmogorov’s descriptive complexity,36, 37 which defines the amount of complexity as the length of the shortest binary computer program that is able to describe an object. In more intuitive terms, the MDL principle is based on the so-called Occam’s razor, interpreted as “If there are many explanations consistent with the observed data, choose the simplest.”37 However, it is hard to compute to Kolmogorov’s descriptive complexity.37 Rissanen suggested that the description length can be regarded as the number of binary bits used for data transmission between a hypothetical pair of an encoder and a decoder.17 This idea is heavily supported by Shannon’s source coding theorem, since the expected description length of data is minimum on average when the true model parameter of the pdf is used.37, 38 Note that this interpretation is parallel to K-L distance, which is zero if and only if the model parameter is true. According to MDL, our task is to measure the total expected codelength to encode the measurement and the model. More specifically, the total code is composed of two parts: one for encoding measurements based on a model and the other for encoding the model itself. Hence, the total code length is described as where is related to the goodness-of-fit with respect to basis to translate it into the code length in bits. The code length , however, is distinct from AIC and SIC. In MDL detrending, the hypothetical encoder should encode the position of each wavelet coefficient as well as its magnitude. If we assume the uniform distribution of the position of coefficients and the optimized truncation for real-valued magnitude,39 the code length for MDL criterion can be written as:28 where and denote the code length for the location and magnitude of the wavelet coefficients, respectively. Since Eq. 30 was originally derived by Saito for a wavelet image compression problem,28 we call this Saito’s MDL.Note that the code length for encoding positions of coefficients in Saito’s MDL can be written as which implies that locations are encoded using Shannon’s coding scheme under the assumption of uniformly distributed coefficients along all decomposition levels. However, considering the smoothness of a global trend, it is not appropriate to assume that all wavelet coefficients have identical probability of being components of the trend estimate regardless of their scale. In practice, we can easily conjecture that coarser scale wavelet coefficients are more likely to be included in the trends.Therefore, we consider an alternative a priori distribution for the wavelet coefficients, whose probability varies across scale. Note that the new code should satisfy Kraft’s inequality, defined as: where denotes a set of binary codes, and denotes the length of the binary codes. Kraft’s inequality is the sufficient and necessary condition for the prefix code that guarantees the unique translation of received code words.37, 38 This is a basic constraint for pdf to be used in the MDL framework. Among a number of pdfs that have scale dependent probabilities, we select the universal prior for integers proposed by Rissanen:39 where , the sum involves only the nonnegative terms, and is defined to bring the left side of Kraft’s inequality to unity. Interestingly, the corresponding code length for this prior assigns a shorter code length for coarser scale wavelet coefficients, as shown in Figs. 1a and 1b . On the contrary, the uniform prior in Saito’s MDL assigns the same code length for all scales. Therefore, the universal prior for integers provides a larger penalty for choosing a finer scale; hence, it prefers a coarser scale trend estimate.By extending this concept, it is reasonable to assign the same code length for wavelet coefficients within the same scale. A slight modification is required in order to give an identical probability to coefficients within the scale. Specifically, suppose denotes the number of wavelet coefficients in the ’th scale. The code length from the modified universal prior corresponding to the ’th scale is then given by where denotes the starting index of the ’th scale wavelet coefficients, denotes the coarsest scale, and is defined in Eq. 33, respectively. This modified universal prior is illustrated in Fig. 1, which exhibits a staircaselike increasing behavior in the code length. The final MDL criterion can therefore be summarized as follows:where . Here, encodes the magnitude, whereas encodes the location.We have observed that both and SIC tend to give an overfitted model for the NIRS signal, as described in the experimental results. This is because the number of temporal NIRS sequences is much larger than that of fMRI data, and it is known that the probability of overfitting is more than zero under quite general conditions, as in these priors.35 However, the MDL criterion does not exhibit such overfitting thanks to its asymptotic optimality. 4.4.Implementation IssuesIn order to make at least one wavelet coefficient free of boundary artifacts, the maximum level of decomposition should allow at least coefficients at the last decomposition level, where denotes the support length of the wavelet. Under this constraint, the maximum level of wavelet decomposition is given by: where denotes an operator that truncates to the nearest integers toward zero. In case the number of wavelet coefficients at the scale is larger than , we allow an additional level of wavelet decomposition by boundary extension of the data so that the number of wavelet coefficients at the coarsest level always becomes . This constraint allows us to use the same form of the modified universal prior of integers regardless of the length of the NIRS time series. More specifically, if the total number of data elongations is , where denotes the number of coefficients in the ’th scale, then we have . Therefore, the maximum decomposition level of the NIRS signal becomes , and the number of wavelet coefficients at the finest scale is . For the specific boundary extension, we employ a symmetric extension.40In order to implement wavelet detrending, the wavelet should be compact. Daubechies wavelets and Symlets22 with small orders are therefore reasonable candidates. However, due to the small vanishing moment of these wavelets, the trend estimate often violates the assumption of smoothness. Hence, we selected a CDF biorthogonal filter41 with a vanishing moment of 9, which gives a reasonable trade-off between the vanishing moment and the wavelet support. Note that CDF is a standard wavelet filter in lossy compression of JPEG 2000 (Ref. 42), due to the compactness and sufficient vanishing moments. 5.Experimental ResultsWe performed NIRS experiments using Oxymon Mk III (Artinis, Netherlands), which has eight laser diodes and four detectors. In this system, two continuous wave lights ( and ) are emitted at each source fiber. A suitable arrangement using 24 pairs of a source and a detector are illustrated in Fig. 2a . Sources and detectors were attached by optical fibers on the scalp covering the motor cortex, as illustrated in Figs. 2b and 2c. The distance between the source and detector was . A 3.0T MRI scanner (ISOL, Korea) was also used to simultaneously measure the BOLD signal. The echo planar imaging (EPI) sequence was used with , flip , 35 slices, and slice thickness. In the subsequent anatomical scanning session, T1-weighted structural images were acquired using the same system. Fig. 2RFT experiment setup. (a) Arrangement of optodes. Eight black circles denote receivers, and eight gray circles denote sources. signs correspond to 24 source and receiver pairs. (b) Overall position of optodes. (c) Target area for right-finger tapping experiments, which is located at the motor cortex of the left hemisphere.  To evaluate the proposed detrending algorithm, nine healthy, right-handed male adults were examined using a right-finger tapping (RFT-1) task. The periods of activation were alternated with periods of rest. During the activation periods, subjects were instructed to tap right-hand fingers. Total recoding time was . In addition, one subject was examined under the same conditions; however, in this time, the subject did not receive any stimulus during the recording period, which we call the baseline. This baseline data is used for a subsequent simulation study. No subject had any history of neurological disorders. All subjects were informed about the whole experiment process. The investigation was approved by the Institutional Review Board of Korea Advanced Institute of Science and Technology (KAIST). 5.1.Simulation StudyFor comparison, two detrending methods based on the conventional filtering8 were implemented. First, finite impulse response (FIR) filters were designed using the Kaiser window method, whose cutoff frequencies were appropriately adjusted for each case.43 In addition, we also compared our method with DCT-based filtering, a standard detrending technique in SPM.15 DCT coefficients that are below the cutoff frequency were declared as trend estimates. Note that we utilized the symmetric extension at both ends of the NIRS data to reduce boundary distortion during filtering. A simulated NIRS time series was constructed to have a global bias, a simulated task-related time series, and AR(1) noise (auto-regressive noise of order 1). Note that the autoregressive (order 1) plus white noise model is a standard model for serial correlations in fMRI-SPM (Refs. 15, 44) from the empirical perspectives, and the AR(1) model has successfully explained the short-range correlations.44 Hence, this simulation also employs the AR(1) model to account for the short-range correlations in NIRS time series. The global bias was extracted from the real NIRS experiment under the baseline condition using a low-pass filter whose stopband edge was . The hemodynamic response was modeled by the canonical HRF with its derivatives. The extracted trend was normalized to [0,2], and the magnitude of the hemodynamic response was set to 1.05. The AR(1) noise was generated by , where was set to 0.8, and is the vector whose elements are zero mean white Gaussian variables with variance . The noise covariance matrix is then given by: This covariance matrix was used in calculating -scores in Eq. 11.In Figs. 3a and 3b, the simulated NIRS time series and its components are illustrated. Black lines in Figs. 3c, 3d, 3f show global trend estimates using various detrending methods. The same cutoff frequency for simulating the ground-truth trend was used in Fig. 3d, which represents the case where the frequency content of a global trend is exactly known. In Fig. 3e, a FIR filter with a stopband edge of is used. Figure 3f is the result of DCT-based filtering whose cutoff frequency is . Even in the case where the exact cutoff frequency is known, as illustrated in Fig. 3d, it was hard to distinguish between the hemodynamic signal and the global trend when both signals have the same frequency contents. Indeed, the hemodynamic signal is an extremely low frequency signal considering the sampling frequency of NIRS, and hence it is sometimes similar to the global bias in its frequency content. We can easily see that the Wavelet-MDL-based detrending method (Wavelet-MDL) gives a much closer estimate for the unknown bias, as illustrated in Fig. 3c. For a quantitative analysis, Table 1 shows the -score using Eq. 11, which confirms that the proposed detrending method shows the best performance in estimating the hemodynamics signals. Fig. 3(a) A synthetic hemodynamic response (black line) and a noise added signal (gray line). (b) The overall simulated signal (gray line) and a ground-truth trend. Trend estimates using (c) Wavelet-MDL, (d) FIR with cutoff frequency , (e) FIR with cutoff frequency , and (f) DCT with cutoff frequency . Wavelet-MDL gives a closer estimate for the unknown trend.  Table 1t -scores with distinct detrending methods.
Recall that the value in the AR(1) model denotes the degree of correlation between the neighborhood samples. Even though this paper chose to represent relatively strong correlation between the neighboring samples, similar behaviors have been obtained for a wide range of values, and our Wavelet-MDL framework has been observed to outperform the other methods for all cases. 5.2.Experimental NIRS DataWe now apply our algorithm to real NIRS measurements. For calculating -values, we used NIRS-SPM software, which has been developed by our group.11 NIRS-SPM allows the estimation of the temporal correlation and determines a -value using the tube formula. For a detailed discussion on the estimation of the temporal correlation, -value, and related threshold value, readers can refer to our previous work on this issue.11 In NIRS-SPM, the conventional filtering based on DCT is implemented. We set the cutoff frequency as , which is below the frequency of RFT paradigm repetition frequency of . In Fig. 4a, the deoxy-hemoglobin (HbR) -map from NIRS-SPM using Wavelet-MDL is illustrated. For clear comparison, the magnified figure is illustrated in Fig. 4b, whereas Fig. 4c shows the result of the conventional DCT filtering approach. The temporal covariance was estimated using a prewhitening method.11 While the task-related activation is observable in both cases, Wavelet-MDL provides a higher -value centered at the target area. The maximum -values were 13.95 and 13.16 for Wavelet-MDL and the DCT-based filtering, respectively. The higher -values indicate that the proposed method provides a statistically more significant estimate of the activation map. Fig. 4Deoxyhemoglobin -maps for the RFT experiment. (a) Result from NIRS-SPM. Magnified -maps using (b) Wavelet-MDL and (c) the conventional method. The wavelet-MDL detrending method provides a higher -value centered at the target area.  An oxyhemoglobin time series and trend estimates are illustrated in Fig. 5 . Since the design matrix is explicitly incorporated during the detrending process of Wavelet-MDL, as described in Eq. 20, the oxyhemoglobin signals were almost conserved, as shown in Fig. 5a. However, in the case of the conventional approach, some components of oxyhemoglobin signals were classified as global trends, as illustrated in Fig. 5b. Figure 6 shows another oxyhemoglobin signal that contains a rapidly varying bias. If we use the conventional detrending method, the residual of the fast-varying transient trend can be classified as an oxyhemoglobin signal. However, Wavelet-MDL can estimate the unknown trend even if it has high-frequency transient signal, since it is capable of capturing the transient signal and adjusting the complexity of a global trend automatically, as illustrated in Fig 6a. However, in Fig. 6b, the fast varying trend was not fully captured by the conventional approach, and the hemodynamic signal was damaged. Fig. 5Oxyhemoglobin measurement during the RFT experiment and estimated trend with (a) Wavelet-MDL and (b) the conventional method. The task-related signals are not removed for the case of Wavelet-MDL.  Fig. 6Oxyhemoglobin measurement during the RFT experiment and estimated trend with (a) Wavelet-MDL and (b) the conventional method. Wavelet-MDL is capable of removing fast-varying trends without damaging task-related signals.  Last, we compared MDL with , SIC, and Saito’s MDL. Figures 7b, 7c, 7d show that the estimated trends based on , SIC, and Saito’s MDL result in overfitting, whereas our algorithm correctly captures the trends. This implies that the modified universal prior of the integer is effective in model order selection. 5.3.Group AnalysisGroup analyses were performed using NIRS-SPM software. NIRS data as well as simultaneously recorded fMRI data from nine subjects were used. Figure 8 shows group activation maps for the HbR signal at , which is overlayed on the fMRI activation map at . The Wavelet-MDL detrending method gives more specific localization of the target motor cortex compared to the conventional DCT-based high-pass filtering. To quantify the accuracy of localization, we calculate the receiver operating characteristic (ROC) for the spatial correlation of the NIRS activation map with that of fMRI BOLD. An ROC curve is a graphical plot of “sensitivity” versus “1-specificity” for a binary classifier. In ROC, (0,1) is the point of an ideal classifier, and the diagonal line represents the performance of random guessing. Therefore, the area under the ROC curve is a good indicator of the performance of a classifier. We evaluated our detrending method by measuring the spatial correlation between NIRS activation maps and the fMRI BOLD map. The BOLD map with was assumed as the ground truth in Fig. 9 . The sensitivity and specificity were calculated by changing the threshold values. The ROC analysis in Fig. 9 shows that the proposed detrending algorithm outperforms the conventional high-pass filtering since the area under the ROC curve is largest for Wavelet-MDL. Fig. 8NIRS-SPM group analysis result at . (a) Wavelet-MDL detrending and (b) DCT based detrending. Wavelet-MDL provides a more specific activation map. The mesh image corresponds to the fMRI activation map at . 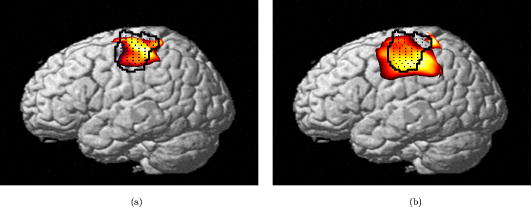 Fig. 9ROC curves for activation maps using Wavelet-MDL and DCT-based detrending. The fMRI activation map at shown as an inset is used as a ground truth, and the sensitivity and the specificity were calculated by changing the threshold value. The ROC analysis shows that the area under the ROC curve for Wavelet-MDL was largest, indicating that the proposed algorithm outperforms the conventional method.  6.Discussion6.1.Temporal Covariance in MDLIn Eq. 26, we assume that the noise is uncorrelated, independent, and normally distributed. For the correlated noise, the covariance matrix should be considered in Eqs. 26, 27, 28. Specifically, consider the negative log-likelihood for measurement in the wavelet domain. Let denote the residual vector for model order in the wavelet domain, i.e., . Since the dependency for on the model order is clear in the context, we omit the letter in the sequel. If we model the correlated noise using the fractional Brownian motion process26 as in the fMRI case,16 the pdf of measurement in the wavelet domain is given by where denotes a diagonal covariance matrix described in Eq. 22. If we substitute Eq. 22 for in Eq. 37, the negative log-likelihood for measurement is then given bywhere is the number of wavelet coefficients in the ’th scale, is the subvector of corresponding to the ’th scale, and is a constant not related to model order selection. The maximum likelihood (ML) estimator for level-dependent variance is easily obtained by a straightforward calculation as follows:which is identical with the ML estimates of the residual variance in the ’th scale. If we substitute Eq. 39 for in Eq. 38:where is a constant not related to model order selection. Now, we employ an exponentially decaying variance model along decomposition levels that is popularly used for modeling the correlated noise in the wavelet domain:24, 45, 46 where is the spectral decay rate of the correlated noise model and denotes a constant that reflects the overall noise variance. We can estimated in the zeroth, decomposition level, i.e., in the time domain, as follows:By substituting Eq. 41 and Eq. 42 for in Eq. 40, we obtainwhere is a constant not related to model order selection. Hence, Eq. 43 is identical to Eq. 28.6.2.-Value versus Activation MapRecall that -value is often used to quantify the performance of the detrending algorithms.16 However, more correct quantification should be based on the accuracy of the activation map at the same -value. For example, consider a case where a fixed -value provides an identical threshold value. Then, in obtaining the activation maps, the overall increase in -values may imply that the resulting activation map becomes significantly larger. Hence, to guarantee the accurate localization, the higher contrast of -value between activated and background region is more important. In this perspective, our group analysis result confirms that wavelet-MDL detrending is more accurate in localizing the activation maps. 6.3.Precoloring versus PrewhiteningIn Ref. 11, we have proposed two different methods to remove the temporal covariance: precoloring and prewhitening. Precoloring tries to remove the temporal correlation by filtering with HRF filter, whereas prewhitening attempts to estimate based on the assumption that the noise is the AR(1) process. In this perspective, the prewhitening provides more accurate estimation of as long as the AR(1) assumption is correct. The -value in Fig. 4 was hence calculated using prewhitening. However, as demonstrated in Ref. 11, precoloring was more robust in removing the temporal correlation, and the final activation maps from precoloring were observed to be better due to the limited number of measurements compared to its fMRI counterpart.11 Hence, this paper calculates the group activation map using the precoloring method, as in. Ref. 11. 7.ConclusionWe developed a Wavelet-MDL-based detrending method that is robust under motion and physiological variation. In Wavelet-MDL detrending, a wavelet transform is applied to the NIRS time series to decompose it into bias, hemodynamic signal, and noise components in distinct scales. With the MDL criterion using a modified universal prior for the integer, the optimal model order could be easily estimated, and the unknown drift signal in NIRS data was successfully removed. Experimental results demonstrated that the new detrending algorithm outperforms the conventional approaches. AcknowledgmentsThis work was supported by the IT R&D program of MKE/IITA [2008-F-021-01]. K. E. Jang gratefully acknowledges support from a Kim Bo Jung Scholarship. K. E. Jang is currently at Samsung Advanced Institute of Technology. ReferencesF. F. Jobsis,
“Noninvasive, infrared monitoring of cerebral and myocardial oxygen sufficiency and circulatory parameters,”
Science, 198 1264
–1267
(1977). https://doi.org/10.1126/science.929199 0036-8075 Google Scholar
S. G. Diamond, T. J. Huppert, V. Kolehmainen, M. A. Franceschini, J. P. Kaipio, S. R. Arridge, and D. A. Boas,
“Dynamic physiological modeling for functional diffuse optical tomography,”
Neuroimage, 30
(1), 88
–101
(2006). https://doi.org/10.1016/j.neuroimage.2005.09.016 1053-8119 Google Scholar
Y. Hoshi,
“Functional near-infrared optical imaging: utility and limitations in human brain mapping,”
Psychophysiology, 40 511
–520
(2003). https://doi.org/10.1111/1469-8986.00053 0048-5772 Google Scholar
M. Cope and D. T. Delpy,
“System for long-term measurement of cerebral blood and tissue oxygenation on newborn infants by near infra-red transillumination,”
Med. Biol. Eng. Comput., 26 289
–294
(1988). https://doi.org/10.1007/BF02447083 0140-0118 Google Scholar
M. Essenpreis, M. Cope, C. E. Elwell, S. R. Arridge, P. van der Zee, and D. T. Delpy,
“Wavelength dependence of the differential pathlength factor and the log slope in time-resolved tissue spectroscopy,”
Adv. Exp. Med. Biol., 333 9
–20
(1993). 0065-2598 Google Scholar
A. Duncan, J. H. Meek, M. Clemence, C. E. Elwell, L. Tyszczuk, M. Cope, and D. T. Delpy,
“Optical pathlength measurements on adult head, calf, and forearm and the head of the newborn infant using phase resolved optical spectroscopy,”
Phys. Med. Biol., 40 295
–304
(1995). https://doi.org/10.1088/0031-9155/40/2/007 0031-9155 Google Scholar
H. Zhao, Y. Tanikawa, F. Gao, Y. Onodera, A. Sassaroli, K. Tanaka, and Y. Yamada,
“Maps of optical differential pathlength factor of human adult forehead, somatosensory motor, and occipital regions at multi-wavelengths in NIR,”
Phys. Med. Biol., 47
(12), 2075
–2093
(2002). https://doi.org/10.1088/0031-9155/47/12/306 0031-9155 Google Scholar
M. L. Schroeter, M. M. Bucheler, K. Muller, K. Uludag, H. Obrig, G. Lohmann, M. Tittgemeyer, A. Villringer, and D. Yves von Cramon,
“Towards a standard analysis for functional near-infrared imaging,”
Neuroimage, 21 283
–290
(2004). https://doi.org/10.1016/j.neuroimage.2003.09.054 1053-8119 Google Scholar
M. M. Plichta, S. Heinzel, A. C. Ehlis, P. Pauli, and A. J. Fallgatter,
“Model-based analysis of rapid event-related functional near-infrared spectroscopy (NIRS) data: a parametric validation study,”
Neuroimage, 35 625
–634
(2007). https://doi.org/10.1016/j.neuroimage.2006.11.028 1053-8119 Google Scholar
P. H. Koh, D. E. Glaser, G. Flandin, S. Kiebel, B. Butterworth, A. Maki, D. T. Delpy, and C. E. Elwell,
“Functional optical signal analysis: a software tool for near-infrared spectroscopy data processing incorporating statistical parametric mapping,”
J. Biomed. Opt., 12 1
–13
(2007). https://doi.org/10.1117/1.2804092 1083-3668 Google Scholar
J. C. Ye, S. Tak, K. E. Jang, J. Jung, and J. Jang,
“NIRS-SPM: statistical parametric mapping for near-infrared spectroscopy,”
Neuroimage, 44
(2), 428
–447
(2009). https://doi.org/10.1016/j.neuroimage.2008.08.036 1053-8119 Google Scholar
K. J. Worsley and K. J. Friston,
“Analysis of fMRI time-series: revisited again,”
Neuroimage, 2 173
–181
(1995). https://doi.org/10.1006/nimg.1995.1023 1053-8119 Google Scholar
J. Sun,
“Tail probabilities of the maxima of Gaussian random fields,”
Ann. Probab., 21
(1), 34
–71
(1993). https://doi.org/10.1214/aop/1176989393 0091-1798 Google Scholar
J. Cao and K. J. Worsley,
“The geometry of the Hotellings random field with applications to the detection of shape changes,”
Ann. Stat., 27
(3), 925
–942
(1999). https://doi.org/10.1214/aos/1018031263 0090-5364 Google Scholar
Statistical Parametric Mapping: The Analysis of Functional Brain Images, Academic Press, San Diego, CA
(2006). Google Scholar
F. G. Meyer,
“Wavelet-based estimation of a semiparametric generalized linear model of fMRI time-series,”
IEEE Trans. Med. Imaging, 22
(3), 315
–322
(2003). https://doi.org/10.1109/TMI.2003.809587 0278-0062 Google Scholar
J. Rissanen,
“Modeling by shortest data description,”
Automatica, 14
(5), 465
–471
(1978). 0005-1098 Google Scholar
K. J. Friston, A. P. Holmes, K. J. Worsley, J.-P. Poline, C. D. Frith, and R. S. J. Frackowiak,
“Statistical parametric maps in functional imaging: a general linear approach,”
Hum. Brain Mapp, 2
(4), 189
–210
(1995). https://doi.org/10.1002/hbm.460020402 1065-9471 Google Scholar
R. W. Cox,
“AFNI: software for analysis and visualization of functional magnetic resonance neuroimages,”
Comput. Biomed. Res., 29 162
–173
(1996). https://doi.org/10.1006/cbmr.1996.0014 0010-4809 Google Scholar
G. M. Boynton, S. A. Engel, G. H. Glover, and D. J. Heeger,
“Linear systems analysis of functional magnetic resonance imaging in human V1,”
J. Neurosci., 16 4207
–4221
(1996). 0270-6474 Google Scholar
R. N. A. Henson, C. J. Price, M. D. Rugg, R. Turner, and K. J. Friston,
“Detecting latency differences in event-related BOLD responses: application to words versus nonwords and initial versus repeated face presentations,”
Neuroimage, 15 83
–97
(2002). https://doi.org/10.1006/nimg.2001.0940 1053-8119 Google Scholar
S. G. Mallat, A Wavelet Tour of Signal Processing, Academic, New York
(1999). Google Scholar
I. M. Johnstone and B. W. Silverman,
“Wavelet threshold estimators for data with correlated noise,”
J. R. Stat. Soc. Ser. B (Methodol.), 59
(2), 319
–351
(1997). https://doi.org/10.1111/1467-9868.00071 0035-9246 Google Scholar
P. Flandrin,
“Wavelet analysis and synthesis of fractional Brownian motion,”
IEEE Trans. Inf. Theory, 38
(2), 910
–917
(1992). https://doi.org/10.1109/18.119751 0018-9448 Google Scholar
D. Ville, M. L. Seghier, F. Lazeyras, T. Blu, and M. Unser,
“WSPM: wavelet-based statistical parametric mapping,”
Neuroimage, 37
(4), 1205
–1217
(2007). https://doi.org/10.1016/j.neuroimage.2007.06.011 1053-8119 Google Scholar
B. B. Mandelbrot and J. W. Ness,
“Fractional Brownian motions, fractional noises, and applications,”
SIAM Rev., 10
(4), 422
–437
(1968). https://doi.org/10.1137/1010093 0036-1445 Google Scholar
D. Donoho and I. M. Johnstone,
“Ideal spatial adaptation by wavelet shrinkage,”
Biometrika, 81
(3), 425
–455
(1994). https://doi.org/10.1093/biomet/81.3.425 0006-3444 Google Scholar
N. Saito,
“Simultaneous noise suppression and signal compression using a library of orthonormal bases and the minimum description length criterion,”
Wavelets Geophys., 299
–324 1994). Google Scholar
J. Rissanen,
“MDL denoising,”
IEEE Trans. Inf. Theory, 46
(7), 2537
–2543
(2000). https://doi.org/10.1109/18.887861 0018-9448 Google Scholar
K. J. Friston, P. Fletcher, O. Josephs, A. Holmes, M. D. Rugg, and R. Turner,
“Event-related fMRI: characterizing differential responses,”
Neuroimage, 7 30
–40
(1998). https://doi.org/10.1006/nimg.1997.0306 1053-8119 Google Scholar
K. L. Hurvich and C. L. Tsai,
“Regression and time series model selection in small samples,”
Biometrika, 76
(2), 297
–307
(1989). https://doi.org/10.1093/biomet/76.2.297 0006-3444 Google Scholar
G. Schwarz,
“Estimating the dimension of a model,”
Ann. Stat., 6 461
–464
(1978). https://doi.org/10.1214/aos/1176344136 0090-5364 Google Scholar
H. Akaike,
“A new look at the statistical model identification,”
IEEE Trans. Autom. Control, AC-19
(6), 716
–723
(1974). https://doi.org/10.1109/TAC.1974.1100705 0018-9286 Google Scholar
S. Kullback and R. A. Leibler,
“On information and sufficiency,”
Ann. Math. Stat., 22
(1), 79
–86
(1951). https://doi.org/10.1214/aoms/1177729694 0003-4851 Google Scholar
P. Stoica and Y. Selen,
“Model-order selection: a review of information criterion rules,”
IEEE Signal Process. Mag., 21 36
–47
(2004). https://doi.org/10.1109/MSP.2004.1311138 1053-5888 Google Scholar
A. Kolmogorov,
“Three approaches to the quantitative definition of information,”
Probl. Inf. Transm., 1 4
–7
(1965). 0032-9460 Google Scholar
T. Cover and J. A. Thomas, Elements of Information Theory, 2nd ed.John Wiley & Sons, Inc., New York
(1991). Google Scholar
M. Hansen and B. Yu,
“Model selection and the principle of minimum description length,”
J. Am. Stat. Assoc., 96
(454), 746
–774
(2001). https://doi.org/10.1198/016214501753168398 0162-1459 Google Scholar
J. Rissanen,
“A universal prior for integers and estimation by minimum description length,”
Ann. Stat., 11
(2), 417
–431
(1983). https://doi.org/10.1214/aos/1176346150 0090-5364 Google Scholar
M. Unser,
“A practical guide to the implementation of the wavelet transform,”
Wavelets in Medicine and Biology, 37
–73 1996). Google Scholar
A. Cohen, I. Daubeches, and J. C. Feauveau,
“Biorthogonal bases of compactly supported wavelets,”
Commun. Pure Appl. Math., 45
(5), 485
–560
(1992). https://doi.org/10.1002/cpa.3160450502 0010-3640 Google Scholar
B. E. Usevitch,
“A tutorial on modern lossy wavelet image compression: foundations of JPEG 2000,”
IEEE Signal Process. Mag., 18
(5), 22
–35
(2001). https://doi.org/10.1109/79.952803 1053-5888 Google Scholar
A. V. Oppenheim and R. W. Schafer, Discrete-Time Signal Processing, Prentice Hall, Upper Saddle River, NJ
(1989). Google Scholar
P. L. Purdon and R. M. Weisskoff,
“Effect of temporal autocorrelation due to physiological noise and stimulus paradigm on voxel-level false-positive rates in fMRI,”
Hum. Brain Mapp, 6
(4), 239—249
(1998). https://doi.org/10.1002/(SICI)1097-0193(1998)6:4<239::AID-HBM4>3.0.CO;2-4 1065-9471 Google Scholar
E. Bullmore, C. Long, J. Suckling, J. Fadili, G. Calvert, F. Zelaya, T. A. Carpenter, and M. Brammer,
“Colored noise and computational inference in neurophysiological (fMRI) time series analysis: resampling methods in time and wavelet domains,”
Hum. Brain Mapp, 12
(2), 61
–78
(2001). https://doi.org/10.1002/1097-0193(200102)12:2<61::AID-HBM1004>3.0.CO;2-W 1065-9471 Google Scholar
J. M. Fadili and E. Bullmore,
“Penalized partially linear models using sparse representations with an application to fMRI time series,”
IEEE Trans. Signal Process., 53
(9), 3436
–3448
(2005). https://doi.org/10.1109/TSP.2005.853207 1053-587X Google Scholar
|