|
|
1.IntroductionDiabetes mellitus (DM) is one of the most common chronic diseases worldwide and continues to increase in population and significance.1,2 Vascular and neurological disorders in the lower extremities are common complications of DM. Approximately 15% to 25% of patients with DM eventually develop foot ulcers.3 If not adequately treated, these ulcers may ultimately lead to lower extremity amputation.4 The onset of diabetic foot ulcers is preventable by early detection and timely treatment of (pre-)signs of ulceration, such as callus formation, inflammation, and blisters. However, early detection depends on frequent assessment. This is not always possible, because self-examination is difficult or impossible due to the various health impairments caused by DM, and a sufficiently frequent examination by health care professionals would be too intrusive and too costly. Previous studies have shown the feasibility of such frequent assessment with help of telemedicine.5 However, digital photography, as applied in those studies, misses the opportunity for automatic detection, thereby still requiring help from health care professionals. The ultimate objective of our project is to develop an intelligent telemedicine monitoring system that can be deployed for frequent examination of the patients’ feet to timely detect (pre-)signs of ulceration. That is, we want to automatically detect (pre-)signs of ulceration in the diabetic foot, and discriminate these from healthy skin. No such system is currently available. Spectral imaging (SI) is a promising modality to achieve this objective. The SI is a hybrid modality for optical diagnosis, which obtains spectral data of the entire measured area and renders it in image form.6 Medical hyperspectral imaging (MHSI) provides a noncontact and noninvasive diagnostic tool that is able to quantify relevant features such as tissue oxygenation and epidermal thickness.7 Impairments in these features play an important role in the development of diabetic foot ulcerations and their subsequent failure to heal.8 Based on these features, studies have been conducted with the MHSI to assess the risk for ulcer formation,7 to monitor diabetic neuropathy,9 and to predict ulcer healing.10 Besides these three options, an intelligent monitoring system should also be capable of automatically recognizing ulcers and pre-signs of ulceration, such as abundant callus formation, inflammation and blisters, and discriminate these skin spots from healthy skin. This can be achieved with the help of statistical pattern classification techniques. The SI has not yet been used for automatic recognition of (pre-)signs of ulceration in the diabetic foot with statistical pattern classification techniques. 1.1.Statement of the ProblemThe aim of the current article is to describe the methodology for designing an intelligent monitoring system involving SI for the diabetic foot, with spectral data acquired from spectrometer measurements on skin spots. Such a design is hampered by the lack of a physical model signifying the difference between spectral data coming from skin spots that are healthy or (pre-)signs of ulceration (e.g., ulcers, abundant callus formation, inflammation, blisters, etc.). The alternative is an approach that exploits the statistical properties of a training set of spectral data, which has been annotated by an expert clinician. This immediately confronts us with the problem arising from the high-dimensionality of the spectral data acquired by current available MHSI systems. Exploiting the statistical properties by training a pixel classifier using high-dimensional MHSI data tends to overfit,11 i.e., to adapt the classifier to accidental, statistically irrelevant peculiarities in the training set. This problem can be solved by a firm reduction of the dimensionality, by reducing the number of spectral bands (filters) employed in the SI system. Another advantage of such a reduction is that it will also increase the measurement and cost efficiency of the future system. The methodology presented in this article will consist of determining suitable subsets of optical filters for the desired SI system by investigating their performance in discriminating different skin spots. Following, the stability of the selected filters in a simulated SI system will be analyzed with respect to shot noise and small changes of the experimental parameters. 1.2.Outline of the ArticleFigure 1 presents an overview of the followed methodology and an outline of the article. In Sec. 2, the materials for collecting local skin spectral data on feet of diabetic patients with (pre-)signs of ulceration, the measurement procedure and resulting data set are described. In Sec. 3, the statistical analysis is performed on the acquired data to search for suitable subsets of commercial interference bandpass filters. With the selected filters, the stability of the virtual SI system with respect to shot noise and small changes of the experimental parameters is investigated with a Monte Carlo method in Sec. 4. Finally, conclusions and future plans are presented in Sec. 5. 2.Collection of Training Data2.1.Data AcquisitionA spectroscopic system has been built to collect reflectance spectral data from the foot soles of patients with complications caused by diabetes. The experimental setup, as shown in Fig. 2, consists of (1) a spectrometer, (2) a broad-band illumination source, and (3) a reflection fiber optics probe. The reflection probe (6.5-mm diameter) contains 7 fibers: 6 illumination fibers (Fiber 3a) surrounding 1 reader fiber (Fiber 3b). The probe is mounted in a probe holder made from black anodized aluminum, which is placed on the target skin area. It fixes the distance between the probe end and target skin area at 5 mm. In this way, ambient light is blocked and a reproducible illumination under an angle of 45 deg is achieved. The coaxial arrangement of illumination and recording fibers minimizes the influence of superficial scattering and specular reflection on the spectra. The recorded skin spectra cover the wavelength range from 360 to 1000 nm and contain 1127 channels with a bandwidth ranging from 0.6 to 0.53 nm. The measurement area of the skin is around , which is sufficient for small (pre-)signs of ulcerations or a small sample of bigger (pre-)signs of ulcerations. Prior to the acquisition of in vivo skin spectra data for each patient, the dark current, , of the spectrometer is recorded when the light source is off. In addition, a spectrum of a white spectral standard (WS-2, Avantes, Apeldoorn, The Netherlands) is measured. This standard has a near-constant, high diffuse reflectance over the entire wavelength range, which is defined as 100%. The diffuse reflectance spectrum, , of the measured skin region of interest (ROI) is then calibrated according to: where is the measured raw spectrum for the ROI.2.2.Patients Recruitment and Live AssessmentsPatients were recruited from the multidisciplinary diabetic foot clinic of the Hospital Group Twente, Almelo, the Netherlands. The patients included in this study were all diagnosed with diabetes and showed (pre-)signs of ulceration or had a history of ulceration. The average age of the 64 included patients was 65.7 years (; range 35 to 95). The reflectance spectra were collected from skin regions selected by experienced clinicians classified with the following live assessment scores:
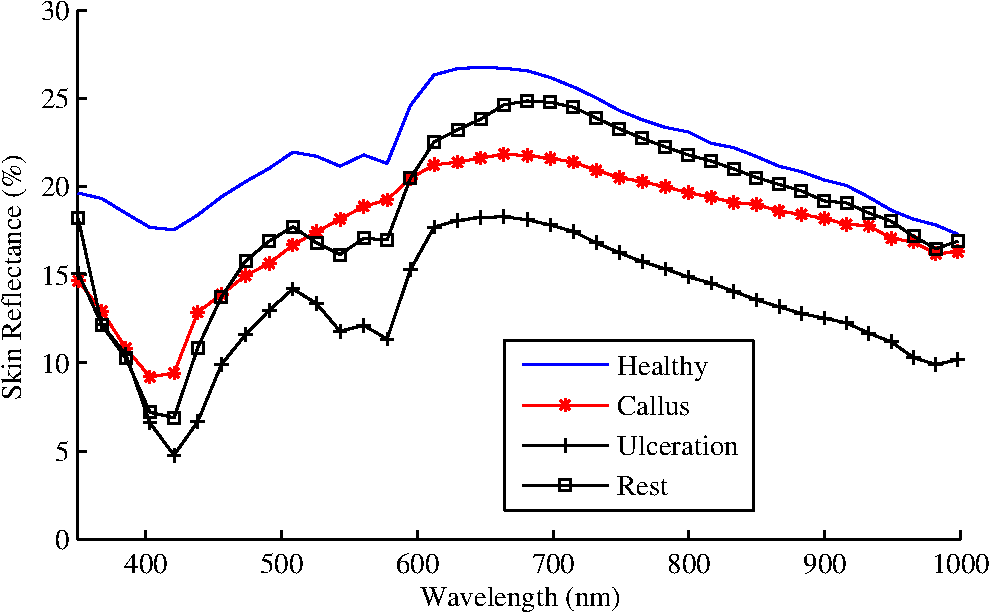
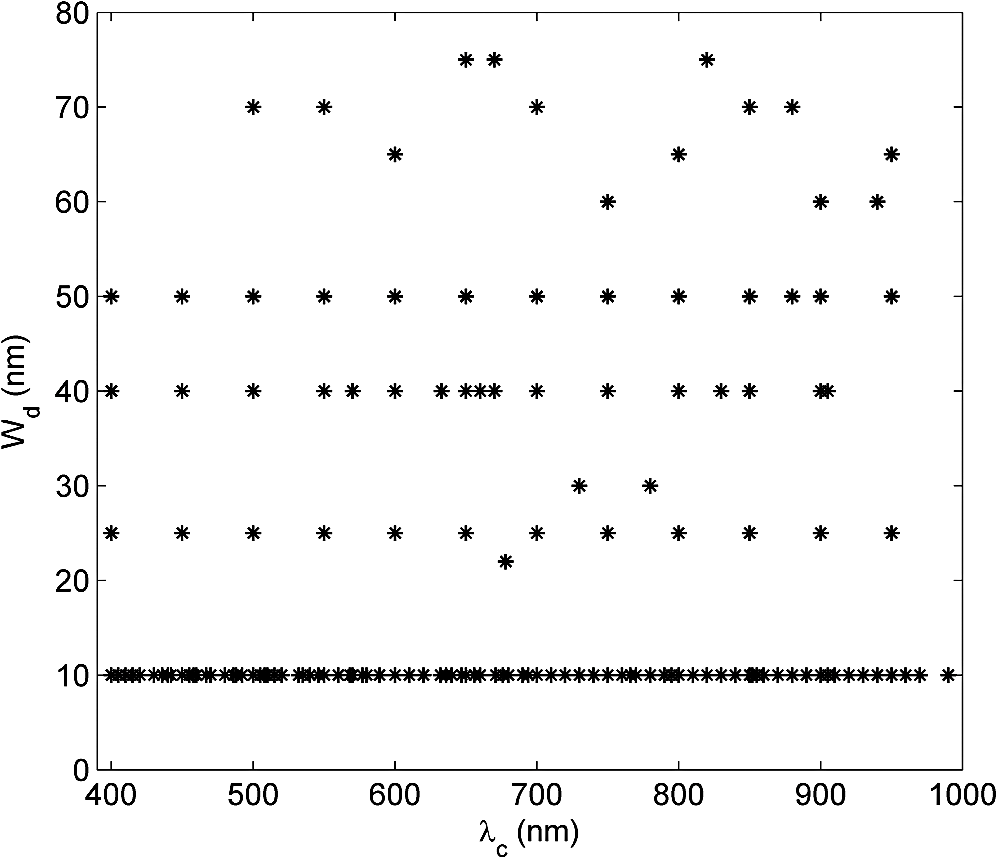
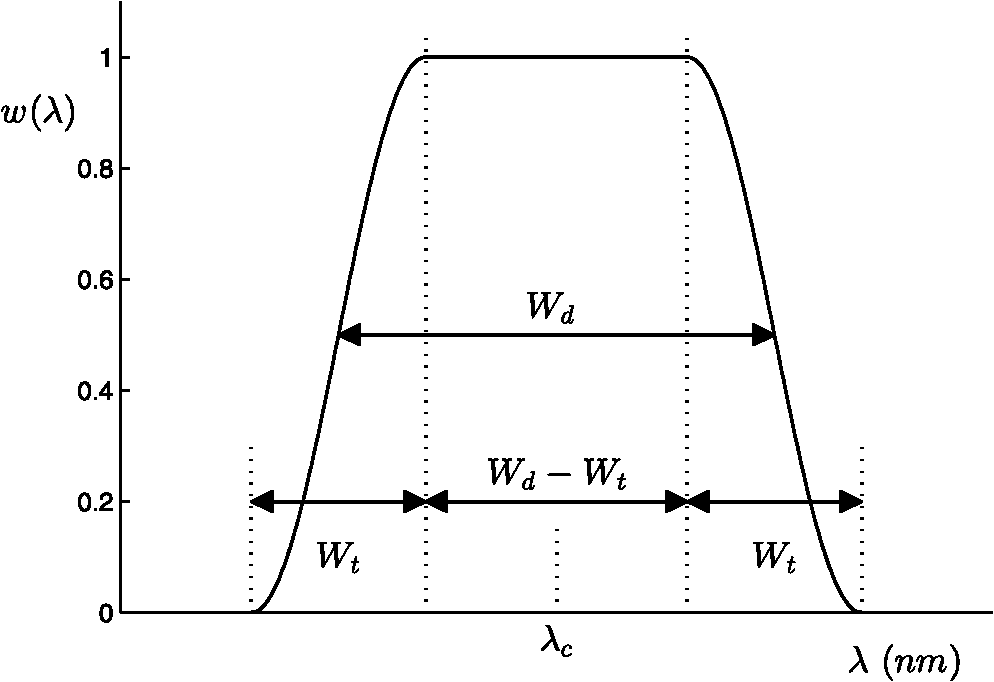
During the measurement, the probe holder was placed on the skin in two directions, which were along the width of the foot and the orthogonal direction. Each ROI was measured two times in each direction. In some cases, when the areas of the ROIs were smaller than or on the edge of the foot, only two measurements along the first direction were performed. At least one “Healthy” ROI was measured on each foot of a patient. The final spectra of each ROI was obtained by taking the average of all the four or two measurements. 2.3.Summary of the Acquired DatasetLocal reflectance measurements were performed on 227 ROIs from 64 patients, among which there were 95 “Healthy,” 55 “Callus,” 38 “Ulcers,” and 39 “Rest.” The “Rest” category bundled several very diverse skin conditions, each of which occurred only infrequently in this study (e.g., 6 necrosis, 5 redness, 3 blister, etc.). In addition, the corresponding areas of some of these ROIs were much smaller than the measurement area, so that no pure spectra could be sampled from them. As a consequence, the within-class variation of the data in the “Rest” category was very large. For this reason, the initial statistical analysis, presented in Sec. 3, only focused on the data from the first three classes, which contained 188 of the measured 227 spectra. Examples of the measurements are given in Fig. 3. 3.Statistical Analysis for Selection of the Optical FiltersIn this section, the statistical analysis will be performed on the acquired skin spectra to search for the most informative optical filters for the future SI system. 3.1.Methodology for Optical Filter SelectionThe functional structure of the statistical analysis is shown in Fig. 4. The database, consisting of the measured and manually classified skin spectra, is fed into a simulator of a large bank of optical filters. The characteristics of these virtual filters match the specifications of real, commercially available bandpass filters. The output data of all simulated filters, as well as the original measured data, is also applied directly to “Classification 1” and “Classification 2” to find the baseline performances, which can help “Filters Selection” to make decisions over the performance of the selected filters. The “Filters Selection” put all the outputs of the simulated filters in a pool to find the (sub-) optimal subset of filters for classifying the measured spectral data. In the subsequent process step “Classification 3”, different classifiers are applied to find the most appropriate one that yields the best performance (i.e., accuracy of classification). Fig. 4The functional structure of the data analysis that is applied to find the optimal subset of optical filters.  To make a comparison between the various selections of filters and classifiers, a relevant measure of the performance, such as the error rate (probability of misclassification), is essential. Since overfitting (resulting in a too optimistic estimate of the error rate) can easily occur if the same data is used both for training and for testing, -fold cross validation and/or leave-one-out cross validation12 is applied to avoid that. The design of a classifier involves two aspects:12 (1) selection of the type of classifier and (2) the training of the parameters of the classifiers. The type of classifier (linear, quadratic, Parzen, etc.) defines the structure of the decision function that maps the features to assigned classes. The more complex the mapping is, the more parameters are needed to be estimated to model the mapping, and the more the classifier is susceptible to overfitting. The complexity of a well designed classifier is a compromise between its ability to adapt its decision boundary to the requirements imposed by the statistical properties of the features at hand and its ability to withstand overfitting. There are two common approaches to reduce complexity, which are feature extraction (FE) and feature selection (FS). The FE approach extracts a set of new features using a simple function that maps the original -dimensional feature space to a lower dimensional space. The features extracted do not have clear physical meanings. The FS approach only selects a subset of existing original features without any mapping. Thus, the FS is the approach that is useful for finding the optimal subset of commercial available optical filters, as presented in Sec. 3.4, whereas the FE will be used in Sec. 3.3 as a reference. 3.2.Simulation of Optical FilteringIn total, 148 interference bandpass filters were simulated, where the central wavelength and the bandwidth of these filters were provided by real filters from two manufacturers: Edmund Optics (York, UK)13 and Comar Optics (Cambridgeshire, UK).14 The ‘s changed from 400 to 1000 nm and the ‘s varied between 10 and 75 nm. An overview of the parameters of all simulated filters is given in Fig. 5. In addition to the parameters that are specified by the manufacturers, a third parameter was assumed to model the steepness of the filter. is the transition width between zero transmission and maximum transmission, which was set to . Figure 6 shows the modelled shape of the transfer function , where represents the full width at half maximum and the transition zone is modelled by half a cosine function. The spot spectra in the data set were denoted by , where is the ROI number, . The filter transfers are denoted by . The filter simulation is accomplished by a numerical approximation of: The filter outputs of each measured area are arranged in -dimensional vectors , called feature vectors. The true class for each ROI is available from the diagnosis by experienced clinicians. This yields a labelled training set of ROIs, classes (, “Healthy,” “Ulcer,” and “Callus”), and with each spot an associated -dimensional feature vector (). 3.3.Baseline PerformanceIn order to find a reference for the effects of filter selection, first the performance of classification was assessed with the original measured data and when all filters were used. Direct application of a linear classifier to the full feature vectors () yielded an error rate as high as 70%. Other classifiers yielded likewise performances. The explanation for this behaviour is overfitting. According to a simple rule of thumb,15 to avoid overfitting in a linear classifier, the number of samples should be at least about five times the number of features (). The present case did not fulfill this, and the number of features should be reduced before applying classification. Linear FE was applied to accomplish that. Linear FE is a linear mapping from to with implemented by a matrix : Two methods are commonly used: linear principal component analysis (PCA) and linear discriminant analysis (LDA). The goal of the PCA is to find the -dimensional linear subspace of that preserves as much variance in the data as possible. Often, is chosen such that, for instance, 99% of the variance is still in the linear subspace. The PCA projection was always scaled by the mean class standard deviations in this article. The LDA is a feature reduction method that takes class information into account. If there are clusters in an -dimensional space, the linear subspace that separates the clusters optimally is at most dimension. Hence, for a data set with classes, the LDA seeks to determine the linear subspace to preserve as much class-discriminatory information as possible: it simultaneously tries to maximize the inter-class distance and to minimize the intra-class distance. If the original feature space is high-dimensional, and the training set small (as in our case), the LDA must be preceded with PCA to prevent numerical instability.12 The dimensionality preserved in the preceding PCA should be optimized by cross validation. In our case, the optimal PCA subspace of the 148-D space is a 28-D space, which is further reduced to a 2-D space by LDA. The features extracted as such are illustrated in the scatter diagram in Fig. 7(a). In Fig. 7(b), the figure also shows the scattering of the two most important PCA features. These two features hold 98% of the variance. Fig. 7Scatter diagrams in two different feature spaces. (a) Shows the feature space that is obtained by linear discriminant analysis (LDA) [preceded by principal component analysis (PCA)]. (b) Shows the space of PCA features solely.  When the PCA and/or the LDA is applied to the filtered data, as in Eq. (3), each extracted feature is a linear combination of the original filter outputs. Therefore, an extracted feature can be regarded as the output of a single virtual filter. If the elements of are denoted by , and the ‘th element from by , then Eq. (3) can be written as: This effectively implements an optical filter with transfer function: The net optical filter transfers for the two LDA components are illustrated in Fig. 8. As shown in Fig. 7, the three classes are discriminated well by the two LDA features, indicating that a simple linear classifier suffices. We verified that by comparing its performance with the ones of a quadratic classifier, a Parzen classifier, a K-nearest neighbor classifier and support vector machine.12 In all cases, the parameters were optimized using 10-fold cross validation. Besides, 10-fold cross validation was also used to assess the performance. Indeed none of them could out-perform the linear classifier, i.e., they all had similar performances, with a mean error rate 9%. Taking the time consumed for training and classification into consideration, the linear and quadratic classifiers were chosen for the filter selection. With LDA as the FE and a linear classifier, the error rate of the full set of filtered data was (obtained with 10-fold cross validation). Exactly the same result was obtained with 28 PCA extracted features directly classified by the linear classifier, instead of indirectly via LDA. Following the same procedure to extract 2 features using LDA (preceeded by PCA), the original measurement data (1127 spectral measurements per ROI) achieved an error rate that was almost the same. The averaged error rate differed . We conclude that the simulated filtering did not cause much information loss/gain, and an error rate of would be used as the baseline, i.e., the reference performance. For illustrative purposes, both of the error rates, from the original measurements (1127-D space) and the data after filtering (148-D space), will be presented in the following sections. 3.4.Optical Filter SelectionTo select filters with the FS techniques, i.e., to find a subset of features corresponding to the full set of filters, two choices have to be made: the search strategy to select candidate subsets, and the search criterion to evaluate these candidates. Among the available searching strategies,16,17 the optimal search methods are not applicable, because their searching complexity grows combinatorially. The suboptimal strategies build up the subsets either incrementally (forward), or decrementally (backward). When searching for a relative small subset ( filters), backward selection is not adequate. Among the three forward strategies, which are sequential forward selection, plus--take-away- selection, and sequential floating forward selection (SFFS), the most versatile approach, the SFFS, was chosen.17 The search criterion can be either a measure of the statistical distance of the class differences in the data, or it can be the estimated error rate of a classifier that is applied to the subset, the so-called wrapper. In this article, one measure, the Mahalanobis distance, and two wrappers, the linear discriminant classifier (LDC) and the quadratic classifier (QDC) are studied. Both wrappers are evaluated with leave-one-out cross validation to avoid overfitting during searching. To make a comparison between the various selections of filters and classifiers, a relevant measure of the performance, such as the error rate (probability of misclassification), is essential. The main light-absorbing factors are melanin in the epidermis, and oxy-haemoglobin () and deoxy-hemoglobin (Hb) in the dermis. The local concentration of each of these factors influences the measured skin spectrum in a specific way. In particular, absorption features a strong maximum around 412 nm and additional maxima at 542 and 577 nm, while Hb exhibits peaks at 430 and 555 nm.18 Thus, these five wavelengths could provide more information about physical parameters, e.g., the epidermal thickness and the oxygen saturation.19,20 The filter selection was carried out in two different ways: (1) all features/filters had the same eligibility and (2) a constrained selection procedure was done in which center wavelengths, around the five wavelengths listed above, were evaluated and preselected with LDC. Once a subset of filters has been found, the subset must be evaluated empirically. This can be done with any type of classifier. Preliminary research showed that parametric-free classifiers, e.g., Parzen, did not perform better. Hence, we selected LDC and QDC once again for empirical evaluation. 10-fold cross validation was used to assess the error rate. 3.4.1.Filter selection without preselectionThe evaluation results are shown in Fig. 9. The SFFS strategy may return with a smaller number of features than the number that is requested when it detects that addition of features does not improve the search criterion. Six features were returned when using LDC as the searching criterion, while four features were returned when using QDC as the searching criterion. When comparing the performances, the observations are:
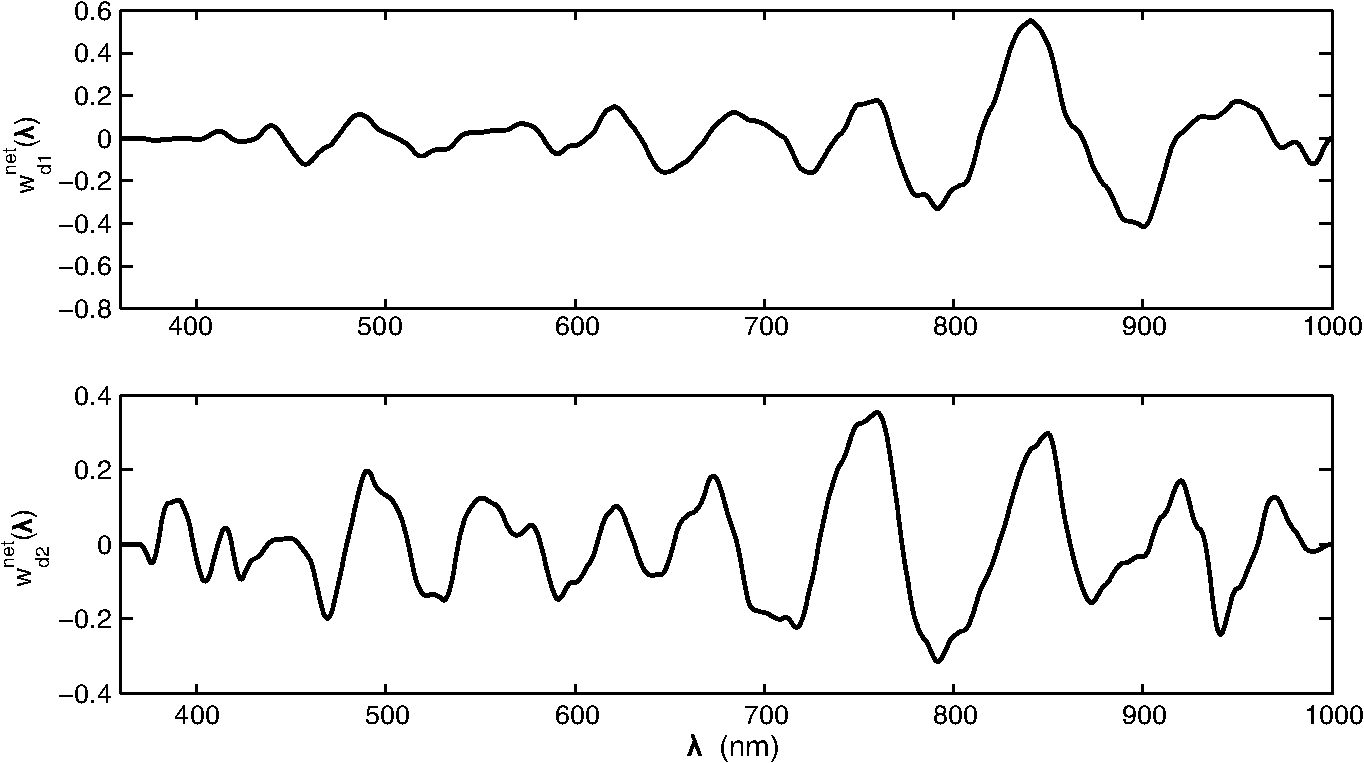
Fig. 9Classification accuracy for sequential floating forward selection (SFFS) with different criterions, linear discriminant classifier (LDC) as classifier (solid lines) and quadratic classifier (QDC) as classifier (dashed lines) for empirical evaluation. The gray color bands represent baseline error rate achieved with features extracted from LDA with LDC as classifier with the original spectra data (1127-D), while the red colour bands represent the baseline achieved with the features extracted from LDA with LDC as classifier with the spectra data after filtering (148-D). 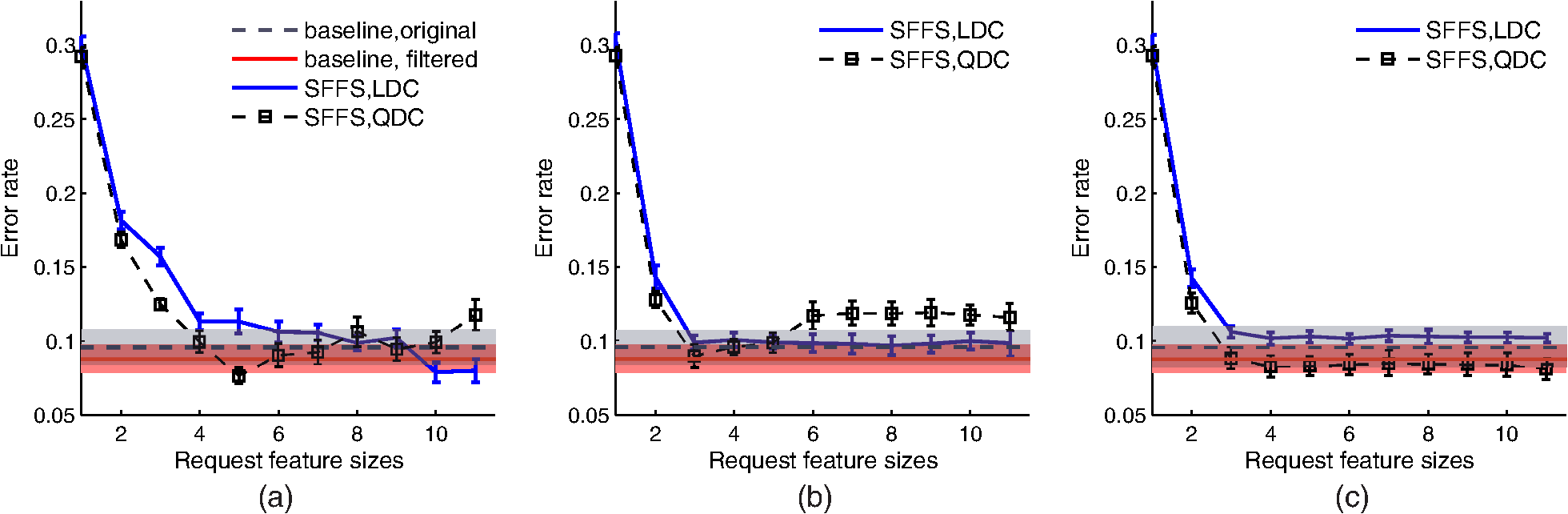 The found subsets are given in Table 1. As can be seen in Fig. 10, each subset seeks information in the range of 550 to 600 nm, and the LDA features are formed by differentiating filter outputs. This results in a large impact on noise sensitivity, to be discussed in Sec. 4. The Mahalanobis distance seeks additional information in a range around 400 nm. The LDC and the QDC both find information in the range around 650 nm useful. Table 1The best subsets of filters (unconstrained search). Each filter is defined by the parameter set “λc (Wd)” given in nm.
Fig. 10The net optical filter transfers that produces the two LDA components of the 3-class problem. These transfers, normalized to [0,1], correspond to three feature subsets as given in Table 1.  3.4.2.Filter Selection with pre-selectionIn addition to the five filters predefined, this constrained FS procedure selected up to six other filters from the rest pool. The results are shown in Fig. 11. Ten-fold cross validation was used to assess the error rate. Fig. 11Classification accuracy for the SFFS with different criteria, the LDC as classifier (solid lines) and the QDC as classifier (dashed lines). The feature selection started from 5 predetermined filters.  Again, the QDC as an evaluation classifier often performed better than the LDC. The best results were obtained when QDC was used for the selection criterion as well as for empirical evaluation [Fig. 11(c)]. With 10 features, the number of ulcer ROIs (i.e., 38) is somewhat less than four times the dimension, whereas it should be at least five times to prevent overfitting, according to the rule of thumb.15 Apparently, it paid off to allow quadratic decision boundaries (rather than linear), although the additional parameters for the quadratic boundaries resulted in some performance loss due to overfitting. The QDC in Fig. 11(c) obtains a minimum with seven features. The performance improvement with the additional three features is not statistically significant. The filter parameters ( and , in nm) that are associated with these features are, where the first five are the predefined filters: 540 (10), 430 (10), 400 (50), 580 (10), 550 (40), 730 (30), 410 (10). 3.4.3.The “Rest” classUp to now, the ROIs in the “Rest” category were ignored. As said before, the “Rest” consisted of a number of different subclasses that were often formed by tiny spots closely surrounded by healthy skin, callus, or ulcer. To see how the rest class behaves, Fig. 12 shows a scatter diagram of all spots in the posterior probability space that is spanned by and . Here, represented the 7-D feature vector that was tabulated in Sec. 3.4.2. Fig. 12The scattering of the data set in the posterior probability space and the decision boundaries, under assumption of equal prior probabilities and equal cost of misclassification.  The posterior probabilities were calculated under the assumption of class dependent, Gaussian likelihood functions, as the base of the quadratic classifier.12 The quadratic decision boundaries in the feature space are mapped to linear boundaries in the probability space. When “Callus” and “Ulcer,” with or without “Rest,” were conflated to one class “Unhealthy,” the estimated performances of the subsets selected are listed in Table 2. When “Rest” is included, the sensitivities dropped from to and AUC decreased with 0 to 0.2, while the specificities all raised . Based on the table, all subsets selected with different criteria did similar and sufficient good work in classification. It is still hard to make a choice among these selected subsets. Table 2Performance of the filters selected.a 3.5.Discussion of the Optical Filters SelectionThe four subsets of filters that are presented all operate in the wavelength range around 550 nm. Two selections also operate in the vicinity of 400 nm. These ranges are all in the biomedical window. None of the selections operate above 750 nm. There is some resemblance between the filters that are based on the LDC and the QDC criteria, but apart from that, the different solutions do not have much intersection. The selection of filters is not very critical as different subsets perform equally well. In all subsets, the QDC outperforms the LDC. This suggests that the dispersion of the measurement data is class dependent. For class independent dispersion, the QDC degenerates into LDC. Since the dispersion of data is caused by the skin properties and not by measurement noise, a class dependent dispersion makes sense. The “Rest” class is not included in the classifier design as yet. Figure 12 shows that the “Rest” ROIs are either situated at the three clusters that correspond with “Healthy,” “Ulcer,” and “Callus,” or situated in-between pairs of those clusters. The explanation is that the areas of “Rest” ROIs are smaller than the measurement area. As a consequence, the measured spectra represent a mixed response from the “Rest” ROIs and the surrounding areas belonging to one or several other classes. For instance, all six measurements for necrosis points in the “Rest” category were classified as “Ulcer,” as shown in Fig. 12. On the other hand, three out of five measurements from redness were classified as “Healthy,” one measurement was classified as “Callus” and the other as “Ulcer.”. The same “mixed area” effect occurs in fact also for several ROIs labelled to the other classes. This also explains the phenomenon that the specificity rose when the “Rest” class was added, as shown in Table 2. For a real spectral camera, the pixel size will be much smaller than , the spectrometer measurement area, and the problem will not occur. However, the classifier needs retraining then, because the rest class is not included as yet. 4.Stability AnalysisIn the previous section, the randomness of the data set mainly stemmed from the variations in physical properties of the skin. All other factors were idealized, with transfer functions that were assumably exactly known, and without possible shot noise. This section addresses the stability of the design, i.e., its ability to withstand small deviations of the transfer functions, and the ability to withstand noise. 4.1.Monte Carlo AnalysisThe stability analysis was carried out by means of a Monte Carlo analysis applied to three different configurations of filter subsets and classifiers:
Configuration 1 was chosen since its performance and its parsimony were the best that could be obtained. Configuration 2 was added to see whether the quadratic classifier was less stable than a linear classifier. Configuration 3 was chosen to see whether a large number of filters (a less parsimonious design) would degrade the stability. The Monte Carlo stability analysis was done as follows. After random sampling of the parameter of a configuration, the error rate of that configuration was estimated using 10-fold cross validation. This was repeated 100 times, and the average over these 100 estimates are shown in Fig. 13. The procedure is repeated for four parameters: the center wavelengths , the bandwidths , the widths of the transition band, and the maximum expected number of electrons. The latter parameter determines the signal-to-noise ratio (SNR) of the system. Fig. 13The influence of tolerances of filter parameters and the influence of shot noise. The performance is given in classification error rate. “UNC” and “CON” present unconstrained and constrained selection, respectively.  The manufacturers specify tolerance regions for ’s and ’s. For different ’s and different coating approaches, the tolerances may be different. For example, when , the tolerance is if traditionally coated, and if hard coated. When the tolerance is . When or 30 nm the tolerance is .13,14 Note that the transmission coefficient of the spectral filters, which varies from 30% to 90% for the types of filters considered here,13,14 need not be included in the stability analysis. This is because it can be assumed that the response of a given imaging system (including light source, image sensor, lens, and the filters) is calibrated for each filter using e.g., a white reference standard, and that it remains calibrated during the measurements. However, low transmission coefficients may influence the SNR. The SNR of the imaging system may be another important aspect that affects the classification stability. The random count of electrons, which are generated at the image sensor during the exposure time, defines the image output and decides the shot noise.21 The probability of this count obeys Poisson distribution, and according to that property, the expectation of the count equals its variance, . Then, the SNR can be expressed as which grows with the expected number of electrons. So, is another parameter of interest.Each parameter was submitted to the Monte Carlo analysis by random sampling according to distributions of the parameters that modelled the tolerances:
Then, all features are transformed to the expected electron count using the factor . According to Eq. (6), Gaussian noise was added to each feature with a variance that equals . Finally, the features were back-transformed by a factor . Figure 13 shows the results of the Monte Carlo analysis. The estimated errors all had standard deviations around 1%. 4.2.Discussion of Stability AnalysisWhen comparing the results with respect to the three configurations of filter subsets and classifiers in Fig. 13, no substantial differences in behavior can be observed. The linear classifier is not more stable than the quadratic classifier, and using only four filters instead of seven does not contribute much to stability either. The shape of the filter transfer function is modelled by the bandwidth and by the width of the transition band. Figures 13(a) and 13(b) show that the classification performance is not sensitive to changes of these parameters. The results suggest that such an assumption is not very critical: with extreme values of the modelled transfer functions vary between a rectangular window and a very smooth cosine window, but the performances are not affected. Figure 13(c) shows that shifts of the center wavelengths of the filters may reduce the performance. If an increase of error rate of 1% is permitted (about equal to the uncertainty of the estimated error rate), the standard deviation of the shifts should not be more than about 4 nm. This requirement is equal to the specification of the low-cost commercial filters, so that it can be fulfilled easily when designing the SI system. The most critical parameter appears to be the maximum expected electron count, . The explanation is that the differences between the outputs of filters are important for classifiers to discriminate different classes (as illustrated in Fig. 10). This may drastically reduce the SNR, i.e., even a small amount of noise has a large impact on the difference. Figure 13(d) indicates that should be above to avoid a performance decline due to quantum limitations. In a hyperspectral camera, such a high density of electrons can be realized by (a) powerful illumination, (b) large exposure time, (c) large aperture of the optics, (d) large pixel size, (e) detective quantum efficiency close to 100%, and (f) transmission of the filters close to 100%. However, the ultimate limitation is defined by the saturation level of the image sensor. For a high-quality industrial camera module with 4 Mp resolution, a typical saturation level is . The figure shows that at that level the increase of error rate can be as high as 2%; the subset of seven filters a little higher than the one with four filters. If such a loss of performance cannot be tolerated, the effective electron count can be increased by using a sensor with a large pixel size, and by summing over neighboring pixels or subsequent frames. The price to pay for an increased pixel SNR is increased system costs, and reduction of spatial and temporal resolution. 5.ConclusionThe methodology for designing an intelligent monitoring system for the diabetic foot based on statistical pattern classification of spectral data has been proposed in this article. To avoid the possible overfitting problem arising from high-dimensional spectral data and to design a system with a limited number of optical filters, a FS procedure was applied. This design methodology can also increase the measurement and cost-efficiency of the future system. The number of needed filters in different subsets resulting from FS, ranged between 3 and 7. The sets were all able to automatically discriminate between (pre-)signs of ulceration and healthy skin spots with a specificity of 96% and a sensitivity of 97%. A stability analysis based on the Monte Carlo method revealed that the most critical design factor is the shot noise. The influence of the noise will be negligible if the saturation level of the image sensors is above about electrons. If this cannot be achieved, temporal or spatial averaging in the image should be applied, at the cost of the resolution. One of the limitations of this study was the small training data set in comparison to the abundant number of spectral bands. Such a set needs to be acquired during live assessment of patients using a spectrometer, and is expensive and therefore small. However, cross-validation during selection and evaluation helped in generalizing the analysis of the data set. Further, the “Rest” class could not be involved in the FS process, as this class was a repository of types of disorders that occur only infrequently. These spots were often so small that they fell below the resolution of the spot spectrometer. In a real SI device with a higher resolution this problem will not occur. Also, sensitivity and specificity were acceptable with levels around 90% with the rest class included. The first future step to be taken is to actually build the SI system with the optical filters as determined in this article as an experimental setup first. Based on results obtained with such a setup, other relevant criteria concerning, for example, the ergonomics of the future system can be determined. These criteria will greatly influence the future system, and need to be investigated before issues such as hardware and costs can be extensively discussed. Building an experimental setup containing the SI system with the optical filters described in this article will bring us one step closer to our ultimate goal: an intelligent telemedicine monitoring system that can be deployed for frequent examination of the patients’ feet to timely detect pre-signs of ulceration. Various options exist for application of such a system in daily clinical practice. For example, a system can be deployed at the home of high-risk patients who need close monitoring to prevent hospitalization. Another option may be placement of the system with the general practitioner, to facilitate weekly or monthly screening of both high- and low-risk patients in an automated manner. Future clinical studies are needed to investigate the most cost-effective application of an intelligent telemedicine monitoring system for the diabetic foot in daily clinical practice. AcknowledgmentsThis project is supported by public funding from ZonMw, the Netherlands Organisation for Health Research and Development. The authors are very grateful for the patients who participated in the data collection, and the clinicians in Diabetic Foot Unit, Department of Surgery, Hospital Group Twente, Almelo, The Netherlands. We also appreciate Geert-Jan Laanstra of the Signals and Systems Group, Faculty of EEMCS, University of Twente, who gave us plenty support in building the experimental setup. ReferencesS. Wildet al.,
“Global prevalence of diabetes: estimates for the year 2000 and projections for 2030,”
Diabetes Care, 27
(5), 1047
–1053
(2004). http://dx.doi.org/10.2337/diacare.27.5.1047 DICAD2 0149-5992 Google Scholar
J. E. ShawR. A. SicreeP. Z. Zimmet,
“Global estimates of the prevalence of diabetes for 2010 and 2030,”
Diabetes Res. Clin. Pract., 87
(1), 4
–14
(2010). http://dx.doi.org/10.1016/j.diabres.2009.10.007 DRCPE9 0168-8227 Google Scholar
A. J. Boultonet al.,
“The global burden of diabetic foot disease,”
The Lancet, 366
(9498), 12
–18
(2005). http://dx.doi.org/10.1016/S0140-6736(05)67698-2 LOANBN 1470-2045 Google Scholar
J. Apelqvistet al.,
“International consensus and practical guidelines on the management and the prevention of the diabetic foot,”
Diabetes/Metab. Res. Rev., 16
(1), S84
–S92
(2000). http://dx.doi.org/10.1002/(ISSN)1520-7560 DMRRFM 1520-7552 Google Scholar
C. E. Hazenberget al.,
“Telemedical home-monitoring of diabetic foot disease using photographic foot imaging a feasibility study,”
J. Telemed. Telecare, 18
(1), 32
–36
(2012). http://dx.doi.org/10.1258/jtt.2011.110504 1357-633X Google Scholar
T. Vo-Dinhet al.,
“A hyperspectral imaging system for in vivo optical diagnosis,”
IEEE Eng. Med. Biol. Mag., 23
(5), 40
–49
(2004). http://dx.doi.org/10.1109/MEMB.2004.1360407 IEMBDE 0739-5175 Google Scholar
D. Yudovskyet al.,
“Assessing diabetic foot ulcer development risk with hyperspectral tissue oximetry,”
J. Biomed. Opt., 16
(2), 026009
(2011). http://dx.doi.org/10.1117/1.3535592 JBOPFO 1083-3668 Google Scholar
A. Korzon-BurakowskaM. Edmonds,
“Role of the microcirculation in diabetic foot ulceration,”
Int. J. Lower Extremity Wounds, 5
(3), 144
–148
(2006). http://dx.doi.org/10.1177/1534734606292037 1534-7346 Google Scholar
R. L. Greenmanet al.,
“Early changes in the skin microcirculation and muscle metabolism of the diabetic foot,”
The Lancet, 366
(9498), 1711
–1717
(2005). http://dx.doi.org/10.1016/S0140-6736(05)67696-9 LOANBN 1470-2045 Google Scholar
A. Nouvonget al.,
“Evaluation of diabetic foot ulcer healing with hyperspectral imaging of oxyhemoglobin and deoxyhemoglobin,”
Diabetes Care, 32
(11), 2056
–2061
(2009). http://dx.doi.org/10.2337/dc08-2246 DICAD2 0149-5992 Google Scholar
W. Li,
“Locality-preserving dimensionality reduction and classification for hyperspectral image analysis,”
IEEE Trans. Geosci. Remote Sens., 50
(4), 1185
–1198
(2012). http://dx.doi.org/10.1109/TGRS.2011.2165957 IGRSD2 0196-2892 Google Scholar
F. van der Heijdenet al., Classification, Parameter Estimation and State Estimation An Engineering Approach Using MATLAB, John Wiley & Sons, Chichester, England
(2004). Google Scholar
“Edmund optics catalogue of the interfernce bandpass filters from 400 nm to 1000 nm,”
(2013). http://www.edmundoptics.com/optics/optical-filters/ Google Scholar
“Comar optics catalogue of the interfernce bandpass filters from 400 nm to 1000 nm,”
(2013). http://www.comaroptics.com/components/filters/interference-filters Google Scholar
T. M. Cover,
“Geometrical and statistical properties of systems of linear inequalities with applications in pattern recognition,”
IEEE Trans. Electron. Comput., EC-14
(3), 326
–334
(1965). http://dx.doi.org/10.1109/PGEC.1965.264137 IEECA8 0367-7508 Google Scholar
R. KohaviG. H. John,
“Wrappers for feature subset selection,”
Artif. Intell., 97
(1–2), 273
–324
(1997). http://dx.doi.org/10.1016/S0004-3702(97)00043-X 0004-3702 Google Scholar
A. K. JainR. R. W. DuinJ. Mao,
“Statistical pattern recognition: a review,”
IEEE Trans. Pattern Anal. Mach. Intell., 22
(1), 4
–37
(2000). http://dx.doi.org/10.1109/34.824819 ITPIDJ 0162-8828 Google Scholar
S. Prahl,
“Optical absorption of hemoglobin,”
(2013). http://omlc.ogi.edu/spectra/hemoglobin/index.html Google Scholar
D. YudovskyL. Pilon,
“Rapid and accurate estimation of blood saturation, melanin content, and epidermis thickness from spectral diffuse reflectance,”
Appl. Opt., 49
(10), 1707
–1719
(2010). http://dx.doi.org/10.1364/AO.49.001707 APOPAI 0003-6935 Google Scholar
D. Yudovskyet al.,
“Two-layer optical model of skin for early, non-invasive detection of wound development on the diabetic foot,”
Proc. SPIE, 7555 755514
(2010). http://dx.doi.org/10.1117/12.846078 PSISDG 0277-786X Google Scholar
P. Regtienet al., Measurement science for engineers, 277
–307 Butterworth-Heinemann(2004). Google Scholar
|