
|
|
1.IntroductionComputerized methods of retinal imaging began in the 1970s. Initially there were difficulties with this technology being adopted by eye care professionals (ophthalmologists and optometrists).1 With time, however, these difficulties were overcome through improvements in technology on one hand and a clearer evidence-based criteria for the diagnosis of retinal diseases on the other.1 As a result, these tools are now available at a time when the incidence of retinal pathologies, such as diabetic retinopathy (DR) and age-related macular degeneration (AMD), is sharply increasing2 and, in the case of DR, reaching pandemic proportions.2 Computerized retinal imaging not only provides an enhanced analysis in clinical follow-up, but also screens for the presence of early stages of pathology. Furthermore, telemedicine allows such retinal images to be obtained from remote areas, thereby enabling diagnosis and treatment to occur when a specialized ocular expert is not present.3 Microaneurysms, hemorrhages, exudates and cotton wool spots, drusen, and abnormal and fragile new blood vessels are all indicators of retinal diseases. The tasks of image analysis in the case of DR involve, but is not limited to, early detection of red lesions (microaneurysms and hemorrhages) and subsequent development of bright lesions (exudates and cotton wool spots). In the case of AMD, the imaging needs to detect another bright lesion (drusen) forming in the macula.1 Drusen are small yellow or white concretions that form in the retina and cause damage in the retinal layers directly underneath them. A high-resolution (HR) image contains more information and, hence, increases the accuracy in assessing the size and form and structure of a retinal lesion. Moreover, the ability to resolve micron scale retinal structures allows a better understanding of the biophysics and visual process. The term resolution refers to the ability of an imaging instrument to reveal the fine details in an object. The resolution of an imaging device depends on the quality of its optics, recording (sensor) and display components, and the nature of the input source radiation. In this paper, the term resolution refers to the spatial resolution. Spatial resolution is further divided into axial and lateral resolution. Axial resolution is the ability to distinguish two closely spaced points in the direction parallel to the direction of the incident beam (Fig. 1). Medical techniques such as confocal microscopy, optical coherence tomography (OCT), and ultrasound provide images of an object in the axial direction. The axial resolution depends mostly upon the nature of the input source radiation. For example, the axial resolution of ultrasound is equal to half of the input spatial pulse length, whereas the axial resolution of OCT is equivalent to the coherence length of the incident light source. On the other hand, the lateral resolution is the ability of an instrument to distinguish two closely spaced points in the direction perpendicular to the direction of the incident beam (Fig. 1). The lateral resolution is determined by the width of the beam; the wider the beam, the poorer the lateral resolution. The lateral resolution of an imaging instrument depends mostly on its imaging optics.4 A high numerical aperture (NA) lens can be used to generate a small spot size that can improve the lateral resolution; however, the resolution achieved is rather limited. Furthermore, both monochromatic and chromatic aberration increases with increasing NA.5 Therefore, it is not beneficial to increase the NA beyond a certain limit. The spatial resolution of an imaging instrument can be improved by modifying the sensor in two ways. First, one can increase the pixel numbers, but at the cost of lower signal-to-noise ratio (SNR) and/or longer acquisition time.6 Second, the chip size can be increased; however, the chip size necessary to capture a very HR image would be very expensive.6 An interesting alternative to all these options is to use an image processing method called super-resolution (SR).7 SR imaging was first introduced by Tsai and Huang8 in 1984. It is one of the most rapidly growing areas of research in image processing. A survey of different SR techniques can be found in Refs. 6 and 910. to 11. SR techniques are broadly divided into multiframe SR (classical approach) and single-frame SR. In multiframe SR technique, a set of low-resolution (LR) images acquired from the same scene is combined to reconstruct a single HR image. Multiple images can be taken using the same imaging instrument or different instruments. The goal is to obtain the missing information in one LR image from other LR images. This way the information contained in all LR images are fused to obtain an HR image.9 Several image fusion applications have been investigated in medical imaging.12 In single-frame SR technique, the missing high-frequency information is added to the LR image using learning-based techniques. The learning-based techniques use HR training set images to learn the fine details and the learned information is used to estimate the missing details of the LR images.6 Retinal fundus is the interior of the eye that includes retina, macula, optic disc, and posterior pole. Fundus images are usually taken by a fundus camera and are used by eye care professionals for diagnosis and tracking of eye diseases. In fact, retina-related diagnosis is based largely on the fundus images. In this paper, we compare the performance of various frequently employed SR techniques and examine their suitability for the fundus retinal imaging. To the best of our knowledge, the SR techniques have not been fully applied to retinal images in the past. For each technique, peak SNR (PSNR) and the structural similarity (SSIM) between the super-resolved image and its original are computed. The PSNR is the peak SNR between the original and super-resolved image, in decibels. PSNR is calculated from the mean square error (MSE), which is the average error between the super-resolved image and its original. A higher value of PSNR indicates a better image quality. The SSIM index computes the similarity between the original and super-resolved image. The SSIM accounts the luminance, contrast, and structural changes between the two images. The rest of the paper is structured as follows. Section 2 describes the observation model for SR. The observation model relates the HR image with the observed LR images. Section 3 presents various multiframe SR techniques, where an HR image is obtained by combining a set of LR images. Section 4 presents the learning-based SR techniques. Comprehensive comparisons of various SR techniques using retinal images are included in Sec. 5. Finally, Sec. 6 provides the discussion and conclusion. 2.Observation ModelIt is important to know the parameters that degrade a retinal image before applying any SR method on it. Blur created either by defocus or motion degrades the retinal image quality. Sampling an object at a frequency less than the highest frequency contained in the object produces aliasing. Also, all retinal images contain some level of noise. These image degradation factors can be incorporated into a mathematical model that relates the HR image to the observed LR image. To be more precise, let be an original image, which is degraded by motion blur () followed by camera blur () and decimation effect (). Furthermore, the image is deteriorated by the white Gaussian noise created during the acquisition process. The observation model that relates the HR image to the observed LR image is The SR methods estimate the image degradation model and use it to reconstruct an HR image from a sequence of LR images . Figure 2 shows a schematic diagram of the observation model. By using different values of (i.e., different motion parameters, blur, decimation, and noise), different LR images can be created from an HR image. The practical values of for creating simulated LR images for this study are described in Sec. 5. 3.Multiframe SR ApproachesIn this technique, an HR image is reconstructed from a sequence of LR images. A schematic diagram is depicted in Fig. 3. There are a number of different approaches for reconstructing a single HR image by pooling information from multiple LR images. This paper includes only the most common reconstruction-based SR approaches. Fig. 3A framework of reconstruction-based super-resolution (SR) technique. An HR image can be reconstructed by pooling information from many LR images.  3.1.Interpolation ApproachesInterpolation is one of the simplest ways of improving the resolution of an image. It estimates new pixels within an image’s given set of pixels. The interpolation methods have proven useful in many practical cases. Most of the commercial software, such as Photoshop, Qimage, PhotoZoom Pro, and Genuine Fractals, use interpolation methods to resize an image. However, single-image interpolation methods are incapable of integrating the information that was lost during the image acquisition process.6 Therefore, in this paper we mainly focus on combing a set of LR images to estimate an HR image using nonuniform interpolation methods. The interpolation-based SR methods involve the following three intermediate steps: registration, interpolation, and restoration. Image registration is the process of geometrically aligning a set of LR images of the same scene with reference to a particular LR image called reference image. LR images have different subpixel displacements and rotations from each other. So it is very important to have accurate estimation of motion parameters before fusing them to create an HR image. Inaccurate estimate of motion parameters results in various types of visual artifacts that consequently degrade the quality of the reconstructed image. The registration is performed in either the frequency domain or the spatial domain. The frequency domain approaches for estimating motion parameters are described in more detail in Sec. 3.2. There are various techniques to estimate motion in the spatial domain as well. Keren et al.13 proposed an algorithm based on Taylor expansion, which estimates the motion parameters with subpixel accuracy. Bergen and colleagues14 proposed a hierarchical framework for the estimation of motion models, such as planar and affine methods. Irani and Peleg15 developed an interactive multiresolution approach for estimating motion parameters. To estimate motion parameters, some algorithms map the whole image, while others map only the features that are common among the LR images.16 The HR image and motion parameters can be simultaneously estimated using Bayesian methods. Hardie et al.17 explain one such approach. The Bayesian approaches are described in more detail in Sec. 3.3. Besides registration, the interpolation also plays an important role for estimating an HR image. There are many different interpolation methods, yet the complexity of each method depends upon the number of adjacent pixels used to estimate the intermediate pixels. Commonly used interpolation methods include nearest-neighbor, bilinear and bicubic methods.18 Nearest neighbor is the most basic interpolation method, which simply selects the closest pixel surrounding the interpolated point. The disadvantage of nearest neighbor is the stair-step-shaped linear features visible in the HR image. Bilinear takes a weighted average of the closest neighborhood pixels to estimate the value of the unknown interpolated pixel. Similarly, bicubic takes the closest neighborhood pixels to estimate the value of the unknown interpolated pixel. In both of the latter methods, higher weights are given to the closer pixels.18 Since the shifts among the LR images are unequal, nonuniform interpolation methods are required to fuse all the LR frames into one HR frame. In 1992, Ur and Gross19 developed a nonuniform interpolation method for a set of spatially translated LR images using generalized multichannel sampling theorem.19 There are many other complex interpolation approaches that are used in resizing a single image, such as cubic spline, new edge-directed interpolation (NEDI),20 and edge-guided interpolation (EGI).21 In short, the cubic spline fits a piecewise continuous curve, passing through a number of points. This spline consists of weights and these weights are the coefficients on the cubic polynomials. The essential task of the cubic spline interpolation is to calculate the weights used to interpolate the data. NEDI (Ref. 20) is a covariance-based adaptive directional interpolation method in which interpolated pixels are estimated from the local covariance coefficients of the LR image based on the geometric duality between the LR covariance and the HR covariance. EGI (Ref. 21) divides the neighborhood of each pixel into two observation subsets in two orthogonal directions. Each observation subset approximates a missing pixel. The algorithm fused these two approximate values into a more robust estimate by using linear minimum MSE estimation. These complex interpolation methods are very efficient and preserve most of the image information; however, their processing time and computational cost is higher in comparison with the general interpolation methods. The information obtained from registration methods is used to fuse a set of LR images. While fusing the LR frames, pixel averaging methods are used. These methods blur the image; hence, image restoration methods are also needed to remove the blur.6 Estimation of the blur kernel has an important role in predicting an HR image; however, many SR approaches assume a known blur kernel for simplicity. The known blur kernel can help to estimate an HR image from a set of simulated LR images; however, for real LR images, the motion blur and point spread functions may lead to an unknown blur kernel.22 Many algorithms are proposed in Bayesian framework to estimate the blur kernel. Recently, Liu and Sun22 proposed a Bayesian approach of simultaneously predicting motion blur, blur kernel, noise level, and HR image. The blind deconvolution algorithm has been used when the information about the blur kernel and the noise level are unknown. The registration, interpolation, and restoration steps in the SR method can be conducted iteratively to achieve an HR image from a sequence of LR images using an iterative backprojection (IBP) approach.15 In this method, an HR image is estimated by iteratively minimizing the error between the simulated LR images and observed LR images. This approach is very simple and easy to understand; however, it does not provide a unique solution due to the ill-posed inverse problem. Another easily implementable SR approach is the projection onto convex set (POCS), devised by Stark and Oskoui.23 In this method, constraint sets are defined to restrict the space of the HR image. The constraint sets are convex and represent certain desirable SR image characteristics, such as smoothness, positivity, bounded energy, reliability, etc. The intersection of these sets represents the space of a permissible solution. Thus, the problem is reduced to finding the intersection of the constraint sets. To find the solution, a projection operator is determined for each convex constraint set. The projection operator projects an initial estimate of the HR image onto the associated constraint set. By iteratively performing this approach, an appropriate solution can be obtained at the intersection of the convex constraint sets. 3.2.Frequency Domain ApproachesAnother popular approach for increasing the resolution of an image is the frequency domain approach, initially adopted by Tsai and Huang.8 Many researchers have subsequently expanded this approach to formulate different SR methods. In frequency domain methods, the LR images are first transformed into the discrete Fourier transform (DFT). Motion parameters can be estimated in the Fourier domain by measuring the phase shift between the LR images since spatially shifted images in the Fourier domain differ only by a phase shift.24 The phase shift between any two images can be obtained from their correlation. Using the phase correlation method, both the planar rotation and the horizontal and vertical shift can be estimated precisely.24 To minimize errors due to aliasing, only parts of the discrete Fourier coefficients that are free of aliasing are used. After estimating the registration parameters, the LR images are combined according to the relationship between the aliased DFT coefficients of the observed LR images and those of the unknown HR image. The data, after fusion, are transformed back to the spatial domain and reconstructed. The advantage of the frequency domain method is that it is easy and best suited for the aliased images since aliasing is easier to remove in the frequency domain than in the spatial domain. The disadvantage is that the observation model is limited to global motion, so it works only for planar shifts and rotations.24 Later, the DFT has been replaced by discrete cosine transform (DCT)25 and discrete wavelet transform26 to minimize the reconstruction error. 3.3.Regularization ApproachesSR is an underdetermined problem and has many solutions. Another interesting approach for solving this ill-posed problem is by utilizing a regularization term. The regularization approach incorporates the prior knowledge of the unknown HR image to solve the SR problem. Deterministic and stochastic approaches are the two different ways to implement regularization. The deterministic approach introduces a regularization term, which converts the ill-posed problem to a well-posed one. where is the regularization term and is regularization constant. Various regularization terms have been utilized to solve this ill-posed problem. The constrained least square regularization method uses smoothness, and regularized Tikhonov least-square estimator uses -norm as regularization.27 The -norm does not guarantee a unique solution. Farsiu et al.28 exploited an alternative -norm minimization for fast and robust SR. Zomet and colleagues29 described a robust SR method for considering the outliers. Recently, Mallat and Yu30 proposed a regularization-based SR method that uses adaptive estimators obtained by mixing a family of linear inverse estimators.The stochastic approach, especially maximum a posteriori (MAP) approach, is popular since it provides a flexible and convenient way to include an a priori and builds a strong relationship between the LR images and the unknown HR image. The method proposes to find the MAP estimation of the HR image for which a posteriori probability is a maximum.6 Using Bayes theorem, the above equation can be written as6 where is the likelihood function and is the priori. Markov random field (MRF) is commonly used as the prior model and the probability density function of noise is calculated to determine the likelihood function.11 The HR image is computed by solving the optimization problem defined in Eq. (4). Several models, such as total variation (TV) norm,31 -norm32 of horizontal and vertical gradients, simultaneous autoregressive (SAR) norm,33 Gaussian MRF model,17,34 Huber MRF model,35 discontinuity adaptive MRF model,36 the two-level Gaussian nonstationary model,37 and conditional field model,38 are used for the prior image model.All the above SR techniques assume that the blurring function is known. The blur can be modeled by convolving the image with the point spread function; however, it requires a strong prior knowledge of the image and blur size. The blind deconvolution algorithm can be used when the information about the blur and the noise are unknown. The blind deconvolution SR methods recover the blurring function from the degraded LR images and estimate the HR image without any prior knowledge of blur and the original image.39,40 The blur is calculated from another regularization term as shown in the following equation: The first term is the fidelity term, and the remaining two are regularization terms. The regularization is a smoothing term, while is a PSF term. The regularization is carried out in both the image and blur domain. 4.Learning-Based SR ApproachesLearning-based SR methods extract the high-frequency information, which is lost during image acquisition process, from the external sources (training set images) and integrate this information with the input LR image to acquire a super-resolved image.41–43 The schematic diagram of learning-based SR is depicted in Fig. 4. The training set consists of many HR images and their simulated LR versions. The performance of the learning-based SR methods highly depends upon the training set data. The training set images should have high-frequency information and be similar to the input LR image.41 To reduce the computational complexity, the learning-based methods are usually performed on the image patches. The learning-based SR methods include the following four stages as depicted in Fig. 5. First, the HR patches and their simulated LR version are stored in the training set in pairs. The features of the training set patches are extracted. A number of different types of feature extraction models can be used such as luminance values, DCT coefficients, wavelet coefficients, contourlet coefficients, PCA coefficients, gradient derivatives, Gaussian derivatives, Laplacian pyramid, steerable pyramid, feature extracted from bandpass filter, low- and high-pass frequency components, quaternion transformation, histogram of oriented gradients, etc. A summary of various feature extraction models is found in Ref. 41. Second, features of the input LR patches are extracted. Third, the features extracted from the input patches and training set patches are matched and the best matched pair from the training set is selected. In recent years, a number of learning methods have been proposed to match the features. The most common learning models are best matching, MRF, neighbor embedding, and sparse representation model.41 Fourth, the learned HR features are integrated into the input LR patch to achieve a super-resolved patch. Finally, all super-resolved patches are combined to generate the HR image. The example-based (EB) SR method proposed by Kim and Kwon43 has outperformed several state-of-the-art algorithms in single-image SR. This method is based on the framework of Freeman et al.,42 which collects pairs of LR and HR image patches in the training stage. In the learning stage, each LR patch of the input image is compared to the stored training set LR patches, and using a nearest-neighbor search method a nearest LR patch and its corresponding HR pair are selected. However, this approach often results in a blurred image due to the inability of nearest neighbor. Kim and Kwon43 modified this approach by replacing nearest-neighbor search with sparse kernel ridge regression. In their approach, kernel ridge regression is adopted to learn a map from input LR patch to training set’s HR and LR patch pairs. This method, however, also produces some blurring and ringing effects near the edges, which can be removed using postprocessing techniques.43 Over the last century, there have been extensive studies on sparse representation algorithms. Sparse representation is the approximation of an image/signal with the linear combinations of only a small set of elementary signals called atoms. The atoms are chosen either from a predefined set of functions (analytical-based dictionary), such as DCT and wavelets, or learned from a training set (learning-based dictionary). The main advantage of these algorithms is that the signal representation coefficients are sparse, i.e., they have many zero coefficients and a few nonzero coefficients. To be more precise, consider a finite-dimensional discrete time signal and an overcomplete dictionary , . The aim is to represent signal using dictionary such that the signal representation error , where is the sparse representation vector, is minimized. The sparse representation of a signal is obtained by solving the following optimization problem.44 Sparse representation has become a major field of research in signal processing. Utilizing this approach, several researchers have proposed learning-based SR algorithms.44–49 Sparse representation-based SR computes the sparse approximation of input LR patch and uses the coefficients of approximation to estimate an HR patch. In this method, two dictionaries and are jointly trained from HR and LR patches. There is a need to enforce the similarity of sparse coding between the LR () and HR patch . The dictionary extracted from the HR patch is applied with the sparse representation of the LR patch () to recover the super-resolved patch. The schematic illustration of SR via sparse representation as proposed by Yang et al.45 is shown in Fig. 6. In sparse representation-based approach, the final super-resolved image patch is generated from the combination of sparse coefficients of the LR patch and the HR dictionary; the performance of the method depends upon both the sparse coefficients of LR patch and the HR dictionary. Many researchers have proposed new algorithms to better estimate the HR dictionary and sparse coefficients of the LR image. Dong et al.46 proposed a cluster-based sparse representation model called adaptive sparse domain selection (ASDS) to improve the dictionary. In this approach, the image patches are gathered into many clusters and a compact subdictionary is learned for each cluster. For each image patch, the best subdictionary can be selected that can reconstruct an image more accurately than a universal dictionary. Another study by Dong et al.47 proposed sparse representation-based image interpolation through incorporating the image nonlocal self-similarities to the sparse representation model. The term self-similarity refers to the similarity of image pixel values or structure at different parts of the image. The algorithm included nonlocal autoregressive model as a new fidelity term to the sparse representation model, which reduces the coherence between the dictionaries and, consequently, makes sparse representation model more effective. Dong and colleagues not only estimated better HR dictionary for each image patch, but also utilized the image nonlocal self-similarity to obtain good estimation of the sparse representation coefficients of LR image. Recently, they have proposed two models for extracting sparse coding coefficients from the LR image as close to the original image as possible using nonlocal sparsity constraints. These are the centralized sparse representation (CSR) model48 and the nonlocally CSR (NCSR) model.49 5.SimulationsMATLAB® software (version R2008a) was used to code and/or to run the programs. The MATLAB® codes were downloaded from the websites of respective authors, and the parameters of each method were set according to the values given in their corresponding papers. A computer with the operating system 64 bit version of Windows 7, Intel (R) Pentium (R) CPU G620T 2.2 GHz processor, and 4 GB RAM, was used to run the simulations. The screen resolution was . Retinal fundus images taken with a fundus camera (Non-Mydriatic Auto Fundus Camera, Nidek AFC-230, Gamagōri, Aichi, Japan) were used to run the simulations. The images were taken from the right eye of one of the authors (D.T.) who has no ocular pathology. SR approaches were applied separately for real LR images and simulated LR images. Simulated LR images are viewed as the shifted, rotated, and downsampled version of an HR image. We cropped three important sections () from three different fundus images to run SR in different parts of the fundus image. The cropped sections were the optic disc, macula, and retinal blood vessels, and are shown in Fig. 7. Four LR images were created from these HR images. The shift and rotation parameters were adjusted manually. Horizontal and vertical displacements were set to (0,0), , (2,1), and ) and rotation angles were set to (0, 5, 3, ) deg, respectively, to create four LR images. The downsample factor was set to 2. Finally, Gaussian noise was added to the LR images to maintain a signal-to-noise ratio of 40 dB. The first LR image is the reference LR image, which is a downsampled version of the HR image, with the shift and rotation parameters zero. The reference LR images are shown in Fig. 7 with their original. Figure 8 shows all four LR images that were created from the cropped optic disc image. We used these simulated LR images to recover the original HR image (resolution ) using various SR methods. Fig. 7HR test images created by cropping three different sections of three different fundus images and their corresponding LR version. 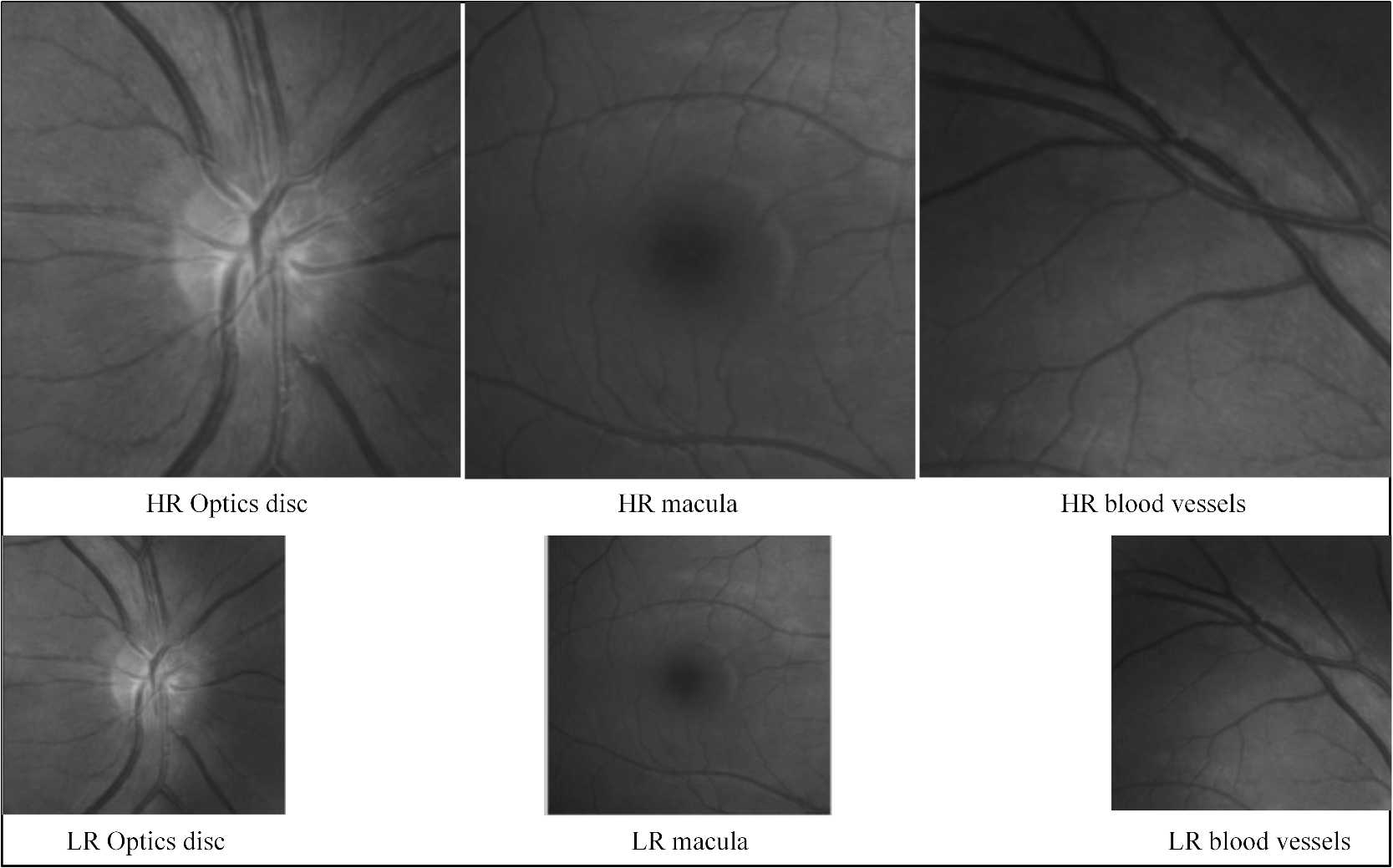 Fig. 8LR images (resolution ) obtained from an optic disc using observation model. These images were used to run all the multiframe SR techniques.  Frequency domain SR approaches24 were first examined on the simulated LR fundus images. These images were transformed into the Fourier domain, and shift and rotation parameters between the LR and reference images were calculated based on their low-frequency, aliasing part. Shifts were estimated from the central low-frequency components in which number of low-frequency components used were 10 and the rotations were estimated from a disc of radius 0.8. By incorporating these motion parameters on the simulated LR images, an HR image was reconstructed using cubic interpolation. Besides cubic interpolation, the performances of IBP,15 robust regularization,29 and POCS23 were also examined in Fourier domain. We employed MATLAB® software prepared by Vandewalle et al.24 to implement these algorithms. For IBP, an upsampled version of the reference LR image was used as an initial estimate of HR image. The upsampling was performed using bicubic interpolation. The IBP created a set of LR images from the initial estimate of HR image using the motion parameters estimated in Fourier domain. The estimate was then updated by iteratively minimizing the error between the simulated LR images and test LR images based on the algorithm developed in Ref. 15. Robust regularization further incorporates a median estimator in the iterative process to achieve better results. We implemented the robust regularization algorithm proposed by Zomet and colleagues.29 The POCS algorithm, which reconstructs an HR image using projection on convex sets, was examined only for the planar shift. Similarly, Bayesian SR methods were studied, and their robustness on the LR fundus images was tested for various prior models. We used algorithms and MATLAB® software prepared by Villena et al.33 for the simulation. TV,31 norm of the horizontal and vertical gradients,32 and SAR33 were used as image prior models. The motion parameters and downsampled factor kept unchanged between the Fourier domain methods and Bayesian methods for fair comparison except for POCS in which planar rotation was not applied. The four simulated LR images were used as input. The algorithm utilized hierarchical Bayesian model where the model parameters, registration parameters, and HR image were estimated simultaneously from the LR images. Variational approximation was applied to estimate the posterior distributions of the unknowns. The algorithm terminated when either a maximum number of iterations () was reached or the criterion , where is the ’th estimated HR image, was satisfied. The Bayesian methods showed the highest PSNR value compared to the other multiframe SR methods. However, the TV norm, norm of the horizontal and vertical gradients, and SAR norm priors model led to oversmooth nonedge regions of the image. Figures 9, 10, and 11 show the results of various multiframe SR approaches applied to the LR images of optic disc, macula, and retinal blood vessels. Table 1 shows PSNR and SSIM indices between the original and the super-resolved images obtained from different multiframe SR approaches. Single-image interpolation methods were also studied on retinal images. The input LR image was created by direct subsampling of the original image by a factor of 2. The LR retinal image was upscaled to its double size using nearest-neighbor, bilinear, and bicubic interpolations. The interpolated images were compared with the original image. The PSNR and SSIM indices for bicubic method were greater than those of the nearest-neighbor and bilinear interpolation. The complex interpolation methods, cubic spline,30 NEDI (Ref. 20), and EGI (Ref. 21), were also applied to the downsampled LR images of optic disc, macula, and retinal blood vessels. Noise was not added to the LR image of single-image interpolation methods, so they showed better PSNR and SSIM indices. The comparisons between the various single-image interpolation approaches in terms of objective quality matrices (PSNR and SSIM) are shown in Table 2. A regularization-based SR with sparse maxing estimators (SME)30 was also examined and showed better PSNR and SSIM indices. Table 1Peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) indices between the original and the super-resolved images obtained from a set of low-resolution simulated images using different multiframe super-resolution (SR) approaches, best values in bold.
Table 2PSNR and SSIM indices between the original and the reconstructed images obtained from various single-image SR approaches, best values in bold.
We examined the EB method proposed by Kim and Kwon43 on the cropped fundus images. We chose this method since it has outperformed many state-of-the art algorithms and also because it removes blurring and ringing effects near the edges.43 The input LR images were created by downsampling the original image by a factor of 2. Noise was not added to the downsampled image. The training set was created by randomly selecting HR generic images. The LR training images were obtained by blurring and subsampling HR images. Thus, the training set constituted a set of LR and HR image pairs. The algorithm was performed on image patches. In this method, the input LR patch was first interpolated by a factor of 2 using cubic interpolation. Next, kernel ridge regression was adopted to learn a map from input LR patch to training set image HR and LR patch pairs. The regression provided a set of candidate images. The super-resolved image was obtained by combing through candidate images based on estimated confidences. The artifacts around the edges of the reconstructed image were removed by utilizing image prior regularization term. Better PSNR and SSIM values are noticed in this method. Similarly, sparse representation-based SR techniques were examined on the LR fundus image. We extracted patches with overlap of 1 pixel between adjacent patches from the input image. The HR dictionaries and sparse coefficients were learned from both the training set HR images and LR test image. We used the method and software proposed by Yang et al.44 to run the simulation. In addition, ASDS,46 sparse interpolation,47 CSR,48 and the most recent NCSR (Ref. 49) methods proposed by Dong et al. were also implemented on LR patches. The latter two methods introduced the centralized sparsity constraint by exploiting nonlocal statics. Both the local sparsity and nonlocal sparsity constraints are combined in this approach. The centralized sparse representation approach approximates the sparse coefficients of the LR image as closely as the original HR image does, which results in better image reconstruction and, hence, better PSNR and SSIM indices. Figures 12, 13, and 14 show the results of various single-image SR approaches applied to the LR images of optic disc, macula, and retinal blood vessels. Finally, multiframe SR techniques were examined on the multiple real retinal images. A fundus camera was fixed manually on the right eye of one of the authors (D.T.) and six consecutive images were taken. The participant’s head was fixed using chin rest. To eliminate pupil constriction, one drop of pupil dilating agent (Tropicamide 1%) was used in the eye. The accommodation effects were also minimized by the dilating agent by paralyzing the ciliary muscles. Six images were acquired with small shifts and rotations due to the eye motions. The images were then cropped to obtain the desired sections. We cropped a small retinal blood vessel section of the fundus image in this study. The sizes of the cropped sections were . One such section is shown in Fig. 15 (top left corner). In the Fourier domain, the shifts between the images were estimated from the central 5% of the frequency and the rotations were estimated from a disc of radius 0.6 as described by Vandewalle et al.24 The images were registered in the Fourier domain and then reconstructed to obtain an HR image using cubic interpolation. The resolution was increased by a factor of two. The robust regularization, IBP, and POCS were also tested on the real images. The results showed that cubic interpolation and POCS methods estimated the blur HR images. These images are worse than the image estimated by a single-image bicubic interpolation method, while the HR images estimated by IBP and robust regularization have better visual quality. A hierarchical Bayesian algorithm was used to estimate the registration parameters in Bayesian methods and the blur was assumed to be a Gaussian with variance 1. We examined TV-prior, L1-prior, and SAR-prior models, but these models led to oversmooth nonedge regions of the image; therefore, combined TV-SAR and L1-SAR prior models were used as described by Villena et al.33 The HR images obtained from these methods are shown in Fig. 15. The image obtained from single-image bicubic interpolation is also shown for comparison. The HR images suffered from registration errors likely due to the fact that most of the SR algorithms work only with planar motion and rotations. The real images, especially retinal images taken from a fundus camera, may have nonplanar motions due to the eye motion. A more precise knowledge of motion parameters is needed to solve this problem. The registration error may also be minimized by taking images from dynamic instruments. Last but not least, we examined blind deconvolution-based SR approach to combine multiple LR images to estimate an HR image as described by Sroubek and Flusser.40 This method does not assume any prior information about the blur; it requires only the approximate size of the blur. In our case, we set blur kernel size. The algorithm built and minimized a regularized energy function given in Eq. (5) with respect to original image and blur. The regularization is conducted in both the image and blur domain. TV regularization was used for our simulation. The HR image predicted by a blind deconvolution method showed a more even spread of the brightness and the edges are sharper and clearer. Among all the above multiframe SR techniques, blind deconvolution showed best results for our LR images. 6.Discussion and ConclusionIn this paper, we demonstrated the possibility of resolution enhancement of retinal images using SR techniques. Three important sections of the fundus images were considered for the simulations: optic disc, macula, and retinal blood vessels. In the first part, we simulated four LR images by shifting, rotating, downsampling, and adding Gaussian noise to an HR image. A number of important features of the fundus image are missing or less clearly visible in the LR images. For example, the arteries and veins emerging from the margins of the optic disc are less clearly visible. The connections between the optic disc and some of the blood vessels are not distinct in the LR optic disc images. The borderlines of blood vessels are less distinct in retinal blood vessels image. Similarly, there are several tiny arteries (cilioretinal arteries) supplying additional blood to the macular region that are also less clearly visible in LR macula images. In addition, the background of the retina is unclear, so recognition of the cilioretinal arteries is also difficult. The foveal reflex is considerably dim in LR macula images. The images were taken from a healthy normal eye; the difference might be more distinct in pathological eyes. SR techniques give magnified image by fusing multiple LR images. The features of an image are also magnified in the same factor, so they are visually clearer in a larger image. This can be seen in many super-resolved images shown in Figs. 9 to 14. The features that are visually less distinct in LR images are more distinct in super-resolved image and the connection between the optic disc and blood vessels is comparatively clearer in super-resolved images given by SME, EB (Ref. 43), and sparse representation44 methods (Fig. 12). However, some SR techniques, for example, sparse interpolation and ASDS, oversmoothed the image, so the important features are lost from the image. The cilioretinal arteries and foveal reflex in super-resolved images given by EB,43 SME, and sparse44 methods are as clear as in the original image, while they are significantly smoothed in super-resolved image obtained from sparse interpolation and ASDS methods (Fig. 13). The other SR techniques show intermediate performance. The super-resolved images have recovered many image features; however, lost edges or textures during the decimation process cannot be recovered completely. The EB (Ref. 43) and sparse representation44 methods show good results and can be used when sufficient number of input LR images are unavailable and/or when higher resolution factor is required. The performance of these algorithms may be improved by using a larger set of training images and by using more relevant learning method. In the second part, we implemented SR techniques on cropped version of six multiple acquisition retinal images taken with a fundus camera. The real images were first normalized, which reduced the effect of different levels of illumination in different images. The Fourier method24 was used to estimate the registration parameters and then these parameters were used to fuse LR images. The Fourier-based cubic interpolation method significantly blurred the reconstructed image. The IBP, robust regularization, and single-image bicubic interpolation method introduced small amount of ringing effect; however, they preserved most of the image features. The Bayesian approaches performed a joint registration and fusion tasks together. They provided visually pleasant image; however, the HR image reconstructed by the Bayesian approaches were oversmoothed and many image details were lost. The blind deconvolution provided much sharper and cleaner reconstructed image than others; however, the HR image was not free of artifacts. Nevertheless, the algorithm is more realistic because it does not need prior information of the blur. In the real image SR approaches, we utilized only six LR images to perform SR; better results can be obtained if number of LR image is increased. Meitav and Ribak50 used retinal LR images to achieve an HR image using a weighted average method. Furthermore, the registration methods are restricted to the planar translational and rotational; however, the eye movements may induce nonplanar variations between LR images. The variations in the ocular surface, such as dynamic nature of the tear film, accommodation and cardiopulmonary effect of the eye, may result in different levels and types of variations between the LR retinal images. Small subpixel error in the registration may result in different estimation. Therefore, robust motion estimation algorithm is essential to perform SR in retinal images. Furthermore, many algorithms, including Bayesian approaches, assume spatially uniform Gaussian blur, which is usually impractical. To avoid damage to the eye, the retinal images are taken in the low-light condition, and therefore, they suffer from low SNR. Most of the SR algorithms deteriorate when noise is present in the image; therefore, a method that is more robust to noise but can also preserve image features is essential. In summary, we demonstrated resolution enhancement of retinal images using image processing methods. While we investigated the performance of various SR techniques, we are unable to present the details of each method. The reader is advised to consult the related reference papers for specific implementation details. Since the codes were downloaded from the websites of respective authors and the parameters of each method were set according to the values given in their corresponding papers, the differences in PSNRs and SSIMs between various SR approaches may be due to the differences in techniques, and/or their parameters. We refer the interested readers to visit the webpage ∼ http://quark.uwaterloo.ca/~dthapa, which contains the MATLAB® source code for various SR techniques developed by several groups of researchers. AcknowledgmentsWe thank School of Optometry and Vision Science, University of Waterloo for providing an opportunity to take retinal images. Special thanks to several authors for providing their respective MATLAB® codes online. We also thank three anonymous reviewers for their constructive comments, which helped us to improve this paper. ReferencesM. D. AbramoffM. Niemeijer,
“Detecting retinal pathology automatically with special emphasis on diabetic retinopathy,”
Automated Image Detection of Retinal Pathology, 67
–77 CRC, Boca Raton
(2010). Google Scholar
H. F. JelinekM. J. Cree,
“Introduction,”
Automated Image Detection of Retinal Pathology, 1
–13 CRC, Boca Raton
(2010). Google Scholar
K. YogesanF. ReinholzI. J. Constable,
“Tele-diabetic retinopathy screening and image-based clinical decision support,”
Automated Image Detection of Retinal Pathology, 339
–348 CRC, Boca Raton
(2010). Google Scholar
J. A. IzattM.A. Choma,
“Theory of optical coherence tomography,”
Optical Coherence Tomography: Technology and Applications, 47
–72 Springer, New York
(2008). Google Scholar
Y. JianR. J. ZawadzkiM. V. Sarunic,
“Adaptive optics optical coherence tomography for in vivo mouse retinal imaging,”
J. Biomed. Opt., 18
(5), 056007
(2013). http://dx.doi.org/10.1117/1.JBO.18.5.056007 JBOPFO 1083-3668 Google Scholar
J. TianK. K. Ma,
“A survey on super-resolution imaging,”
Signal, Image Video Process., 5
(3), 329
–342
(2011). http://dx.doi.org/10.1007/s11760-010-0204-6 1863-1703 Google Scholar
J. D. SimpkinsR. L. Stevenson,
“An introduction to super-resolution imaging,”
Mathematical Optics: Classical, Quantum, and Computational Methods, 555
–578 CRC Press, Boca Raton, Florida
(2012). Google Scholar
R. Y. TsaiT. S. Huang,
“Multiframe image restoration and registration,”
in Advances in Computer Vision and Image Processing: Image reconstruction from incomplete observations,
317
–339
(1984). Google Scholar
S. C. ParkM. K. ParkM. G. Kang,
“Super-resolution image reconstruction: a technical overview,”
IEEE Signal Process. Mag., 20
(3), 21
–36
(2003). http://dx.doi.org/10.1109/MSP.2003.1203207 ISPRE6 1053-5888 Google Scholar
S. Farsiuet al.,
“Advances and challenges in super-resolution,”
Int. J. Imaging Syst. Technol., 14
(2), 47
–57
(2004). http://dx.doi.org/10.1002/(ISSN)1098-1098 IJITEG 0899-9457 Google Scholar
S. BormanR. L. Stevenson,
“Super-resolution from image sequences—a review,”
in Proc. of Midwest Symp. on Circuits and Systems,
374
–378
(1998). Google Scholar
E. Plengeet al.,
“Super-resolution methods in MRI: can they improve the trade-off between resolution, signal-to-noise ratio, and acquisition time?,”
Magn. Reson. Med., 68
(6), 1983
–1993
(2012). http://dx.doi.org/10.1002/mrm.v68.6 MRMEEN 0740-3194 Google Scholar
D. KerenS. PelegR. Brada,
“Image sequence enhancement using sub-pixel displacements,”
in Proc. of IEEE Computer Society Conf. on Computer Vision and Pattern Recognition,
742
–746
(1988). Google Scholar
J. R. Bergenet al.,
“Hierarchical model-based motion estimation,”
Lec. Notes Comput. Sci., 588 237
–252
(1992). http://dx.doi.org/10.1007/3-540-55426-2 LNCSD9 0302-9743 Google Scholar
M. IraniS. Peleg,
“Improving resolution by image registration,”
CVGIP Graph. Models Image Process., 53
(3), 231
–239
(1991). http://dx.doi.org/10.1016/1049-9652(91)90045-L CGMPE5 1049-9652 Google Scholar
D. CapelA. Zisserman,
“Computer vision applied to super-resolution,”
IEEE Signal Process. Mag., 20
(3), 75
–86
(2003). http://dx.doi.org/10.1109/MSP.2003.1203211 ISPRE6 1053-5888 Google Scholar
R. C. HardieK. J. BarnardE. E. Armstrong,
“Joint MAP registration and high-resolution image estimation using a sequence of undersampled images,”
IEEE Trans. Image Process., 6
(12), 1621
–1633
(1997). http://dx.doi.org/10.1109/83.650116 IIPRE4 1057-7149 Google Scholar
Cambridge in Colour, “Digital image interpolation,”
(2012) http://www.cambridgeincolour.com/tutorials/image-interpolation.htm December ). 2012). Google Scholar
H. UrD. Gross,
“Improved resolution from sub-pixel shifted pictures,”
CVGIP Graph. Models Image Process., 54
(2), 181
–186
(1992). http://dx.doi.org/10.1016/1049-9652(92)90065-6 CGMPE5 1049-9652 Google Scholar
X. LiM. T. Orchard,
“New edge-directed interpolation,”
IEEE Trans. Image Process., 10
(10), 1521
–1527
(2001). http://dx.doi.org/10.1109/83.951537 IIPRE4 1057-7149 Google Scholar
L. ZhangX. Wu,
“An edge-guided image interpolation algorithm via directional filtering and data fusion,”
IEEE Trans. Image Process., 15
(8), 2226
–2238
(2006). http://dx.doi.org/10.1109/TIP.2006.877407 IIPRE4 1057-7149 Google Scholar
C. LiuD. Sun,
“A Bayesian approach to adaptive video super resolution,”
in IEEE Conf. on Computer Vision and Pattern Recognition,
209
–221
(2011). Google Scholar
H. StarkP. Oskoui,
“High-resolution image recovery from image-plane arrays, using convex projections,”
JOSA A, 6
(11), 1715
–1726
(1989). http://dx.doi.org/10.1364/JOSAA.6.001715 JOAOD6 1084-7529 Google Scholar
P. VandewalleS. SüM. Vetterli,
“A frequency domain approach to registration of aliased images with application to super-resolution,”
EURASIP J. Appl. Signal Process., 2006 1
–14
(2006). http://dx.doi.org/10.1155/ASP/2006/71459 1110-8657 Google Scholar
S. RheeM. G. Kang,
“Discrete cosine transform based regularized high-resolution image reconstruction algorithm,”
Opt. Eng., 38
(8), 1348
–1356
(1999). http://dx.doi.org/10.1117/1.602177 OPEGAR 0091-3286 Google Scholar
N. NguyenP. Milanfar,
“A wavelet-based interpolation-restoration method for super-resolution (wavelet super-resolution),”
Circuits Syst. Signal Process., 19
(4), 321
–338
(2000). http://dx.doi.org/10.1007/BF01200891 CSSPEH 0278-081X Google Scholar
E. Plengeet al.,
“Super-resolution reconstruction in MRI: better images faster?,”
Proc. SPIE, 8314 83143V
(2012). http://dx.doi.org/10.1117/12.911235 PSISDG 0277-786X Google Scholar
S. Farsiuet al.,
“Fast and robust multiframe super resolution,”
IEEE Trans. Image Process., 13
(10), 1327
–1344
(2004). http://dx.doi.org/10.1109/TIP.2004.834669 IIPRE4 1057-7149 Google Scholar
A. ZometA. Rav-AchaS. Peleg,
“Robust super-resolution,”
in Proc. of the 2001 IEEE Computer Society Conf. on Computer Vision and Pattern Recognition,
I-645
–I-650
(2001). Google Scholar
S. MallatG. Yu,
“Super-resolution with sparse mixing estimators,”
IEEE Trans. Image Process., 19
(11), 2889
–2900
(2010). http://dx.doi.org/10.1109/TIP.2010.2049927 IIPRE4 1057-7149 Google Scholar
S. D. BabacanR. MolinaA. K. Katsaggelos,
“Total variation super resolution using a variational approach,”
in 15th IEEE Int. Conf. on Image Processing,
641
–644
(2008). Google Scholar
S. Villenaet al.,
“Bayesian super-resolution image reconstruction using an l1 prior,”
in 6th Int. Symp. on Image and Signal Processing and Analysis,
152
–157
(2009). Google Scholar
S. Villenaet al.,
“Bayesian combination of sparse and non sparse priors in image super resolution,”
Digital Signal Process., 23
(2), 530
–541
(2013). http://dx.doi.org/10.1016/j.dsp.2012.10.002 DSPREJ 1051-2004 Google Scholar
J. TianK. K. Ma,
“Stochastic super-resolution image reconstruction,”
J. Vis. Commun. Image Represent., 21
(3), 232
–244
(2010). http://dx.doi.org/10.1016/j.jvcir.2010.01.001 JVCRE7 1047-3203 Google Scholar
P. Cheesemanet al.,
“Super-resolved surface reconstruction from multiple images,”
Maximum Entropy and Bayesian Methods, 293
–308 Springer, Netherlands
(1996). Google Scholar
K. V. SureshA. N. Rajagopalan,
“Robust and computationally efficient superresolution algorithm,”
J. Opt. Soc. Am. A., 24
(4), 984
–992
(2007). http://dx.doi.org/10.1364/JOSAA.24.000984 JOAOD6 0740-3232 Google Scholar
S. BelekosN. P. GalatsanosA. K. Katsaggelos,
“Maximum a posteriori video super-resolution using a new multichannel image prior,”
IEEE Trans. Image Process., 19
(6), 1451
–1464
(2010). http://dx.doi.org/10.1109/TIP.2010.2042115 IIPRE4 1057-7149 Google Scholar
D. Konget al.,
“A conditional random field model for video super-resolution,”
in Proc. of the IEEE Int. Conf. on Pattern Recognition,
619
–622
(2006). Google Scholar
F. ŠroubekJ. Flusser,
“Resolution enhancement via probabilistic deconvolution of multiple degraded images,”
Pattern Recognit. Lett., 27
(4), 287
–293
(2006). http://dx.doi.org/10.1016/j.patrec.2005.08.010 PRLEDG 0167-8655 Google Scholar
F. SroubekJ. Flusser,
“Multichannel blind deconvolution of spatially misaligned images,”
IEEE Trans. Image Process., 14
(7), 874
–883
(2005). http://dx.doi.org/10.1109/TIP.2005.849322 IIPRE4 1057-7149 Google Scholar
W. Wuet al.,
“Single-image super-resolution based on Markov random field and contourlet transform,”
J. Electron. Imaging, 20
(2), 023005
(2011). http://dx.doi.org/10.1117/1.3600632 JEIME5 1017-9909 Google Scholar
W. T. FreemanT. R. JonesE. C. Pasztor,
“Example-based super-resolution,”
IEEE Comput. Graph. Appl., 22
(2), 56
–65
(2002). http://dx.doi.org/10.1109/38.988747 ICGADZ 0272-1716 Google Scholar
K. I. KimY. Kwon,
“Example-based learning for single-image super-resolution and JPEG artifact removal,”
(2008). Google Scholar
J. Yanget al.,
“Image super-resolution via sparse representation,”
IEEE Trans. Image Process., 19
(11), 2861
–2873
(2010). http://dx.doi.org/10.1109/TIP.2010.2050625 IIPRE4 1057-7149 Google Scholar
J. Yanget al.,
“Image super-resolution as sparse representation of raw image patches,”
in IEEE Conf. on Computer Vision and Pattern Recognition,
1
–8
(2008). Google Scholar
W. Donget al.,
“Image deblurring and super-resolution by adaptive sparse domain selection and adaptive regularization,”
IEEE Trans. Image Process., 20
(7), 1838
–1857
(2011). http://dx.doi.org/10.1109/TIP.2011.2108306 IIPRE4 1057-7149 Google Scholar
W. Donget al.,
“Sparse representation based image interpolation with nonlocal autoregressive modeling,”
IEEE Trans. Image Process., 22
(4), 1382
–1394
(2013). http://dx.doi.org/10.1109/TIP.2012.2231086 IIPRE4 1057-7149 Google Scholar
W. DongL. ZhangG. Shi,
“Centralized sparse representation for image restoration,”
in IEEE Int. Conf. on Computer Vision,
1259
–1266
(2011). Google Scholar
W. Donget al.,
“Nonlocally centralized sparse representation for image restoration,”
IEEE Trans. Image Process., 22
(4), 1620
–1630
(2013). http://dx.doi.org/10.1109/TIP.2012.2235847 IIPRE4 1057-7149 Google Scholar
N. MeitavE. N. Ribak,
“Improving retinal image resolution with iterative weighted shift-and-add,”
JOSA A, 28
(7), 1395
–1402
(2011). http://dx.doi.org/10.1364/JOSAA.28.001395 JOAOD6 1084-7529 Google Scholar
BiographyDamber Thapa (MSc) is currently pursuing his PhD degree in vision science at the University of Waterloo. He received an MSc degree in vision science from University of Waterloo in 2010. He received an MSc degree in physics from Tribhuvan University, Kathmandu, Nepal. He works in optics of the eye and signal and image processing. His current research interests include wavefront aberrations and adaptive optics of the eye, computer vision, and biomedical image processing. Kaamran Raahemifar PhD joined Ryerson University in 1999. Tenured in 2001, he has been a professor with the Department of Electrical and Computer Engineering since 2011. His research interest is in applications of optimization in engineering. His research team is currently involved in hardware implementation and software-based approaches to signal and image processing algorithms with the focus on biomedical engineering application. He is a professional engineer of Ontario and a senior member of IEEE. William R. Bobier, OD, MSc (University of Waterloo), PhD (University of Cambridge) is a professor of optometry and vision science at the University of Waterloo. His research has covered the optics of the eye, and related binocular motor development. These investigations primarily looked at normal and abnormal developmental patterns in infants and children. Vasudevan Lakshminarayanan PhD, Berkeley has held positions at UC Irvine, Missouri, and Waterloo. He is a fellow of SPIE, OSA, AAAS, IoP, etc. He was a KITP Scholar at the Kavili Institute of Theoretical Physics and is an optics advisor to the International center for theoretical physics in Trieste, Italy. Honors include the SPIE Educator Award and the Beller medal (OSA), and he was an AAAS S&T Policy Fellowship finalist. He is a consultant to the FDA. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||















