|
|
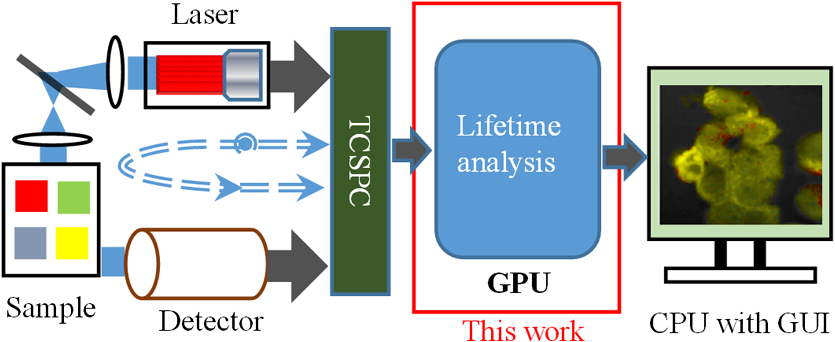
1.IntroductionFluorescence lifetime imaging microscopy (FLIM) is a powerful imaging technique that can not only locate fluorescent molecules (fluorophores) but also provide images based on the temporal decay rate of the fluorescence emitted from fluorophores. In contrast to traditional intensity imaging, FLIM is insensitive to the intensities of light sources and probe concentrations.1 As lifetime characteristics of fluorophores are usually sensitive to their environment, FLIM can image physiological parameters such as pH, O2, Ca2+, Cl−, or temperature linked to diseases or potential therapies. For example, FLIM has been combined with Förster resonance energy transfer (FRET) techniques (FLIM-FRET) for assessing drug efficacy and clearance in tumors,2 cellular temperature in cancerous tissues under treatments,3 and cerebral energy metabolism for understanding brain functions.4 In order to monitor fast dynamic biological events, it is necessary to build a high-speed or even real-time FLIM system.5–7 FLIM can operate in the time domain or frequency domain.8,9 Wide-field frequency-domain FLIM instruments are capable of capturing phase images at a high frame rate, but the acquisition will decrease if more than 10 phase images are required (which usually happens in realistic laboratory scenarios), and accurate analysis heavily relies on appropriate software.10 Moreover, if there is more than one decay component in a fluorescence histogram, excitations at multiple frequencies11 or at a single frequency with a sufficiently narrow pulse (using higher-order harmonic frequencies) are required,12 greatly reducing the acquisition rate and increasing the system complexity. Time-domain techniques, on the other hand, include gated camera13 and time-correlated single-photon counting (TCSPC) methods. Due to superior temporal resolution and recent developments in advanced laser sources and cameras, TCSPC techniques have been the gold standard solutions for FLIM experiments.14–16 Traditional photomultiplier tube (PMT) based TCSPC instruments are capable of single-photon detection, and they can have multiple channels to boost the acquisition. The latest multichannel TCSPC systems16–19 can acquire image raw data in seconds, but the FLIM images are mainly processed by slow analysis software. Recent advances in semiconductor technologies have allowed single-photon detectors to be fabricated in two-dimensional (2-D) arrays in a low-cost silicon process with integrated on-chip TCSPC modules.20–22 These highly parallel single-photon avalanche diode (SPAD) arrays can be configured for wide-field or multifocal multiphoton microscopy systems to enhance the acquisition rate.16 Faster acquisition means more image raw data are generated in a shorter period of time. Similar to the multi-PMT TCSPC system, 2-D SPAD+TCSPC arrays in a single chip significantly enhance the parallelism, enabling real-time acquisition.21,23 And the data throughput of the latest 2-D SPAD arrays can easily exceed tens of gigabit/s, imposing significant challenges in data handling and image analysis.21 In such systems, lifetime analysis has become a bottleneck for real-time FLIM applications. To address this problem, several noniterative fast FLIM algorithms have been developed, including rapid lifetime determination (RLD),24,25 the integral equation method (IEM),26 the center of mass method (CMM),23,27 the phasor method (PM),28,29 moment methods,30 and fast bi-exponential solvers, including bi-exponential centre of mass method (BCMM)31 and the four-gate method.32 To boost image generation, high-performance hardware can be employed to process the imaging data. For example, Li et al. have previously implemented field programmable gate array (FPGA) embedded FLIM processors capable of offering video-rate FLIM imaging.23 These hardware embedded FLIM processors, however, only generate single-exponential FLIM images and are less flexible than traditional iterative algorithms, such as maximum likelihood estimation (MLE),33 the least square method (LSM),33,34 and global analysis (GA).35–37 Compared with noniterative methods, iterative algorithms have the following advantages: (1) they have a wider working range, so that they can be employed in most situations; (2) they can support bi- or multiexponential analysis; and (3) they have better precision and accuracy performances. But iterative algorithms are generally slow and cannot be sped-up easily, and are also difficult to realize in hardware. In this paper, we will focus on how the latest graphics processing units (GPUs) can be used to increase the lifetime estimation speed for both noniterative and iterative algorithms. The work developed in this paper can be a fast FLIM processor between the SPAD-array or multi-PMT acquisition front-ends and the GPU shown in Fig. 1. The realization of parallel FLIM analysis and its optimization will be given in Sec. 2, including a brief introduction of the algorithms. In Sec. 3, we will compare the GPU analysis with CPU parallel analysis and verify the new GPU FLIM analysis methods on both synthesized data and experimental data. 2.MethodologyTo generate a lifetime image requires a FLIM analysis algorithm to process a large number of pixels with each pixel containing a decay histogram. Instead of calculating lifetimes in a pixel-by-pixel manner, it is desirable to analyze all histograms in parallel for real-time applications. Although FPGA technologies have already been introduced in this emerging area,38 their usage is still limited since only the hardware-friendly algorithms, such as RLD, IEM, and CMM,23–27 can be implemented. GPUs, on the other hand, contain a massive number of cores, offering significant computing power, and allow more complex algorithms for data analysis. Therefore, GPUs show great potential in real-time FLIM applications. 2.1.Fluorescence Lifetime Imaging Microscopy AlgorithmsAssume that the measured densities are and for single- and bi-exponential decays, respectively. , , and are the lifetimes, is the prescalar, and is the proportion, and the instrumental response function and background noise are neglected as in the model demonstrated by Leray et al.29 These assumptions allow a proper comparison among different algorithms. Many FLIM algorithms (both noniterative and iterative methods) have been developed for the past few decades. This paper examines some single-exponential and bi-exponential analysis algorithms, including IEM, CMM, LSM, PM, BCMM, and GA, to demonstrate how GPUs can speed up FLIM analysis. The fundamental function for each method can be found in Table 1 for noniterative algorithms and Table 2 for iterative algorithms: Table 1Calculation function of fluorescence lifetime imaging microscopy (FLIM) noniterative algorithms.
Note: IEM, integral equation method; CMM, center of mass method; PM, phasor method; BCMM, bi-exponential centre of mass method; M is the number of time bins; Nj and tj are the photon number and the delay time of the jth bin, respectively; N0 is the count number of the first time bin; h is the width of the time bin; Cj is the coefficient of Simpson’s rule; and τD is the lifetime of the donor.29 Table 2Calculation function of FLIM iterative algorithms. Note: LSM, least square method; GA, global analysis; n is the number of lifetime components; Ni,j is the photon number of the jth bin of the ith pixel; and NGA is the number of pixels in the same segment for GA. 2.2.Graphic Processing UnitGPUs, originally used for real-time rendering, have been used increasingly in general purpose computing (for example, in many biomedical or clinical applications where image analysis is expected to be in real time39–44), with the advent of the Common Unified Device Architecture (CUDA)45 and general purpose GPUs (e.g., NVIDIA Tesla).46 Due to their highly parallel architecture (the NVIDIA Tesla K40 used in this work has 2880 parallel cores), high computational density, and memory bandwidth (), GPUs can accelerate the computing speed dramatically. The latest GPU can reach over 5500 Gflops (floating point operations per second).47 2.3.Graphic Processing Unit ImplementationAll the algorithms introduced above can be translated into GPU programs using the CUDA application programming interfaces.46–48 In this section, we describe how to implement noniterative and iterative algorithms on GPUs. From this section, one can also understand why a GPU works faster than a CPU. We assume the FLIM image to be analyzed contains , and the histogram in each pixel has 256 time bins. In GPU programming, the program is launched as grids of blocks of threads (the left-hand charts of Figs. 2 and 3 show the relationships among thread, block, and grid).47 And instead of being executed only once or a few times in a regular C program, it is executed times in parallel by different CUDA threads.47 Fig. 2Relationships among thread, block, and grid, and GPU implementation of noniterative algorithms for FLIM analysis. 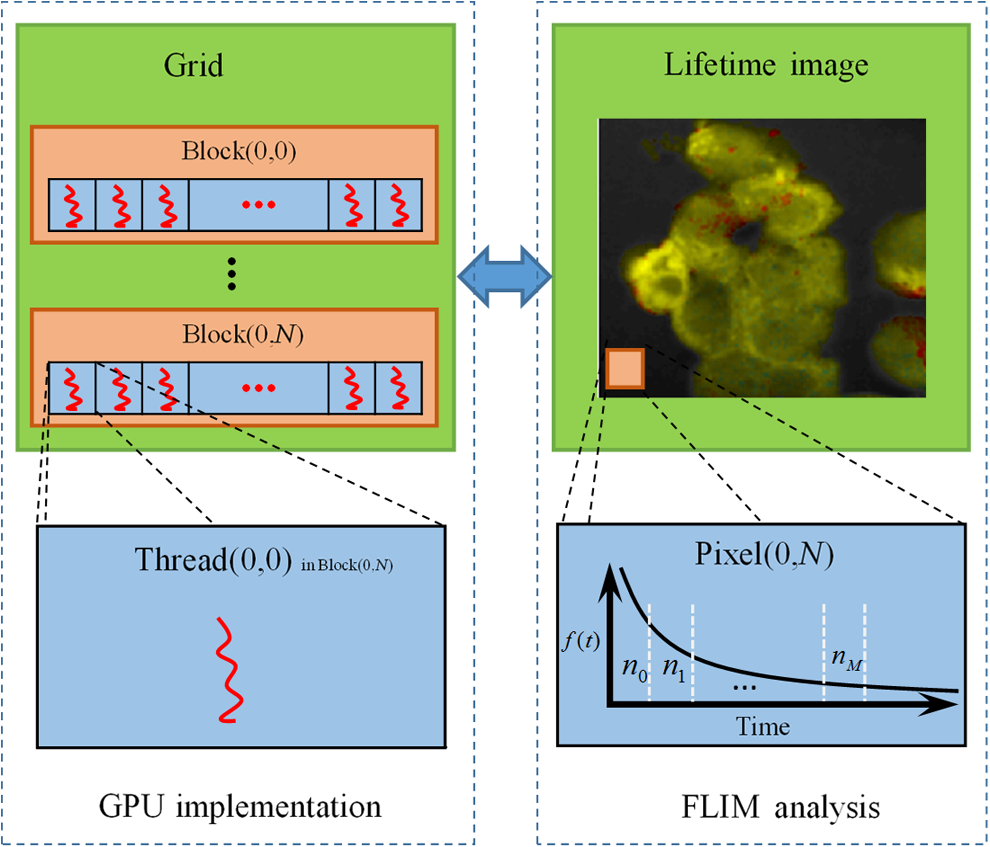 Fig. 3Relationships among thread, block, and grid, and GPU implementation of iterative algorithms for FLIM analysis.  2.3.1.Thread-based computing for noniterative algorithmsFor noniterative algorithms, GPU and CPU programs share similar code, except for the specific configurations of hardware resources and memory accesses in GPU implementations. The histogram of each pixel is analyzed by an independent CUDA thread, as shown in Fig. 2, and each block contains 512 threads. This configuration allows analyzing a large number of pixels simultaneously, the exact number being determined by the number of streaming multiprocessors (SMPs). In this case, up to 30,720 pixels can be launched on the NVIDIA Tesla K40 GPU.47 Then, following the single instruction multiple threads mechanics,49 the lifetime estimations can be realized in parallel, instead of calculating lifetimes in a serial pixel-by-pixel manner as on a CPU. 2.3.2.Block-based computing for iterative algorithmsFor iterative algorithms, the histogram for each pixel is analyzed by a separate CUDA block, as shown in Fig. 3 (here, each thread processes a single time bin, instead of an entire pixel as in noniterative algorithms), and each such block contains 256 threads that correspond to the 256 time bins. This configuration still also allows a quite large number of pixels to be analyzed simultaneously, and 120 pixels are expected on the NVIDIA Tesla K40. Here, we take LSM as an example to demonstrate how to implement iterative algorithms on GPUs. The CUDA operations can be divided into the following two categories. Thread-independent operationFor those operations that are independent in each time bin, the CUDA provides a basic instruction. For example, subtraction or division for each time bin can be finished in only one instruction cycle of one instruction as shown in Fig. 4(a) (here, we just take subtraction as an example, since division follows the same procedure), whereas there are 64 subtraction cycles in the CPU-OpenMP operation [Fig. 4(b)]. In Fig. 4(a), and are stored in the variables SubA and SubB, respectively, and every thread has these two variables, whereas the CPU defines two arrays (SubA[256] and SubB[256]) for loop operations. Thread-exchanged operationAlternatively, the CUDA provides a special solution for some operations where communication or data sharing with other time bins (threads) is necessary. As shown in Fig. 5(a),50,51 the data of each time bin is stored in the th element of a shared memory array SumA (shared memory is on-chip high-speed memory, which enables the threads in the same block to access the same memory content; arrays are defined by: __shared__ SumA[256], in CUDA programming47). In step 1, the first threads compress the array SumA into 128 elements by combining the th and ()th units () simultaneously, followed by several similar steps. Finally, after only steps (it is not a requirement that the number of threads in a block has to be a power of 2, but it maximizes performance), the summation reduction result can be acquired, instead of after 65 steps in the CPU-OpenMP version as shown in Fig. 5(b). 2.4.Optimization of Graphic Processing Unit ProgrammingIn order to maximize the ability of the GPU in FLIM analysis, it is necessary to consider the specifications of GPU hardware, manage the memory properly, and design a specific programming strategy for each individual algorithm. The following considerations are mainly for iterative algorithms, except the kernel configuration and overlap of data transfer, which are also applicable to noniterative algorithms. 2.4.1.Kernel configurationWhen we launch the kernel in a host (CPU), which is the entrance to GPU processing, similar to the main function in the C language, a proper size of block (determining how many threads in a block) and grid (determining the number of blocks) should be given in order to optimize the GPU performance. On CUDA GPUs, 32 threads are bound together into a so-called warp, which is executed in lockstep. Accordingly, it is suggested that the number of time bins should be a multiple of 32, for instance, 256. Furthermore, according to the GPU hardware specification, at most 2048 threads or 16 blocks can be launched in an SMP, which is the workhorse of the GPU46 and puts a different constraint on the number of threads. Table 3 illustrates that for thread numbers that are not multiples of 32, although fewer threads are launched, the processing time can be longer. This is due to the so-called warp divergence, which occurs if threads in the same warp follow different conditional branches in the code. In CUDA, diverging threads in a warp are executed serially, and branch divergences therefore lead to considerably slower execution. Additionally, when the thread number is 224, although it is a multiple of 32, its operation time is longer than expected: . This is because for each SM, only threads have been launched, so that not all the hardware resources are being used. Table 3Operation time under different block size of LSM graphic processing unit (GPU).
In this case, considering a FLIM image to be generated, we examine the performance of GPU FLIM with a different grid size. As shown in Table 4, for FLIM analysis, the calculation times for different sizes are almost the same, so there is no need to configure the block dimension as long as it follows the limitation (maximum grid size of NVIDIA K40: 47). Table 4Operation time under different grid size of LSM-GPU.
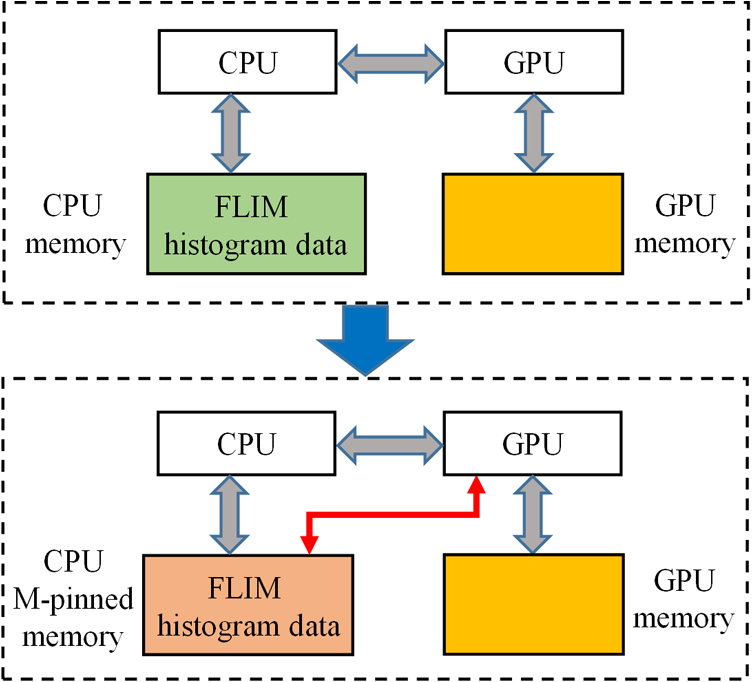
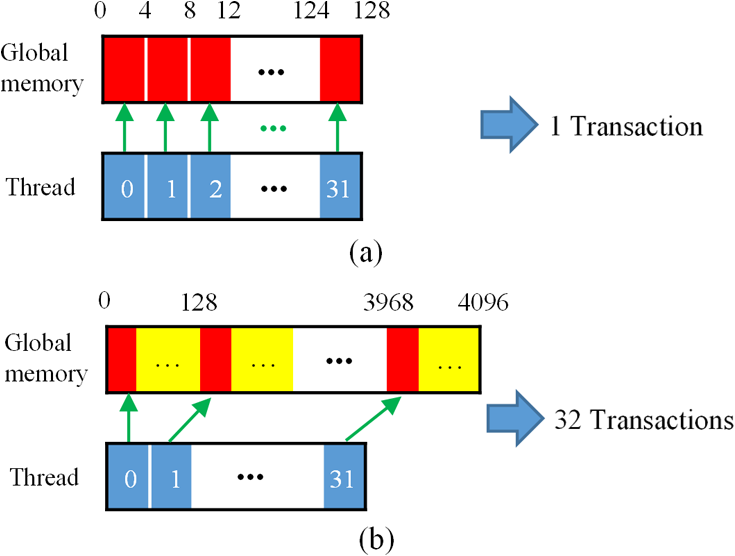
Although simple algorithms use different configurations (i.e., different size of grid or block), the same features can be found as illustrated above. 2.4.2.Memory optimizationIn order to achieve higher performance, it is necessary to optimize the memory usage and maximize the memory throughput. For FLIM analysis, three aspects should be considered as follows. First, for a real-time FLIM process, the GPU has to access the histogram data from the CPU for every image frame, so mapped pinned (M-pinned) memory should be encouraged, which is the host memory and has been page-locked and mapped for direct access by the GPU, as shown in Fig. 6.46 Also, to minimize data transfers between the host (CPU) and device (GPU), the GPU FLIM analysis only uses device memory once the histogram data have been transferred from the host. Moreover, when a large amount of data is used, it is important to consider asynchronous and overlapping transfers with computations.52 CUDA streams (which are sequences of operations that are performed in order on the device) can be used to fulfill this mission. As shown in Fig. 7(a), in sequential mode, the kernel can only be launched after all the data have been transferred to the GPU memory. In contrast, for the concurrent mode, the pixels of an FLIM image are divided into several groups, and each pixel within the same group will be launched in the same stream. As illustrated in Fig. 7(b), histogram or lifetime data transfer and calculation kernels are separated into different streams. This configuration allows data transfer and kernel execution to run simultaneously, and can reduce the whole processing time measurably. Last but not least, GPUs have several memory spaces including the shared, global, constant, texture, register, and local memory,47,52 and for GPU performance, the most important area is memory management.52 Among these memories, the shared memory is on-chip memory, and it has much higher bandwidth and much lower latency than the local or global memory. It is highly recommended that the shared memory should be used as much as possible, especially when there is communication between threads in the same block (e.g., summation reduction operations). However, shared memory is very limited in size, and it is unavoidable to use the large global memory. Because this is by far the slowest memory accessible from the GPU, care should be taken to access it in the most efficient way. CUDA supports so-called coalesced memory access, where several threads of a warp access a congruent area of device memory in a single memory fetch. Using coalesced access as much as possible is very important to minimize the necessary bandwidth. Figure 8 illustrates the difference between the coalesced access and noncoalesced access, and the ensuing large speed difference.47,53 To be specific, this implies, for example, that for noniterative algorithms, the histogram data need to be arranged such that the data of the same time bin but different pixels are directly adjacent, since each thread will access data of the same time bin of the corresponding pixel. For iterative algorithms, however, data of each time bin of a pixel have to be stored in continuous memory locations. Besides, the constant and texture (optimized for 2-D spatial locality) memory spaces, which are cached and read only, can be used to save constant arrays or matrices used in the algorithm and can also speed up the processing. For example, for IEM, every pixel uses the same coefficients , and we can calculate the value before processing, so can be kept in the constant memory (declared by “__constant__ float CoIEM[]”). 2.4.3.Programming strategiesThe first consideration is to trade the precision for the speed when it does not affect the result, such as using single-precision operations instead of double-precision ones. Then the number of divergent warps (threads in the same warp have different operations) that cause delay is minimized. Figure 9 shows a simple example how to avoid divergence. It demonstrates that shifting elements by changing the index can be used to reduce the divergence in some circumstances. More importantly, we try to reduce the number of waiting threads; for example, we execute two summation reductions together in different directions, as shown in Fig. 10, and unroll the last warp in Fig. 5(a). Moreover, CUDA provides some libraries (e.g., cuBLAS) and GPU versions of math functions, and using these resources can not only boost the performance but also reduce the difficulty of CUDA programming, for example, using “__fdividef()” for floating point division. 3.ResultsTo demonstrate the advantage of the proposed GPU-FLIM tool, algorithms were tested on both synthesized and experimental data, and the results were compared with CPU solutions. Results were compared in terms of the performances, that is, precision in FLIM analysis, and the time of processing, that is, their speed. The results are based on an NVIDIA Tesla K40 GPU and an OpenMP CPU implementation on an Intel(R) Xeon(R) E5-2609 v2 processor with four cores. Worth mentioning is that all the results of GPU processing time include the data transfer between CPU and GPU, namely, transferring histogram data to the GPU for processing and moving lifetime results back to the CPU. 3.1.Simulations on Synthesized DataFor single-exponential decays, we assume the target FLIM image is a square with bars, where the lifetime gradually increases from left to right and every pixel within the same bar has the same lifetime (2, 2.5, 3, 4 ns), as shown in Fig. 11(a). The image contains , photons have been collected for each pixel, and each histogram has 256 bins with the bin width of 100 ps. Both CPU- and GPU-based algorithms use single-precision operations and have identical outputs, although they have different architectures, namely, latency oriented versus throughput oriented, respectively. We observe that all algorithms generate effective results in agreement with the known ground truth and that the iterative algorithm provides similar or better results, as shown in Figs. 11(b)–11(d). Fig. 11FLIM images of single-exponential decays: (a) theoretical lifetime image, (b) IEM, (c) CMM, and (d) LSM.  For bi-exponential decays, every pixel has the same lifetime (,), whereas decreases from 0.8 to 0.2 from left to right of the image. Table 5 demonstrates the details of this simulation. The results of different algorithms are given in Figs. 12(b)–12(d), where 32 means a segment of GA contains 32 pixels,35–37 compared with the true image as in Fig. 12(a). From these images, we can learn that all the algorithms generate satisfactory results when , whereas the GA shows great potential as it can resolve a wider range of . Table 5Details of bi-exponential simulations.
Fig. 12Images based on synthesized bi-exponential data: (a) theoretical average lifetime image, (b) PM(c) BCMM, and (d) GA-32.  Tables 6 and 7 show the processing time and speed enhancement of the GPU implementation against the CPU parallel implementation. In Tables 6 and 7, we also included the acquisition rates of recently reported FLIM systems18,19 for comparison. These systems are all for images, but we extended them for ones in order to make a proper comparison. For the latest FLIM systems, the acquisition can range from 0.02 to 2.5 fps (note that the frame rate reported in Ref. 13 will be much slower if more gates are used as suggested in their experimental section). It shows that the acquisition would be the bottleneck if simple algorithms are applied, unless wide-field acquisition is applied.23 Tables 6 and 7 also show that GPUs do offer speed enhancement when a more precise analysis (using GA-32 or LSM) is needed, and the analysis frame rate is comparable to the acquisition rate. Due to different structure and processing schemes, the enhancement factor for each algorithm is different. Table 8 gives a deeper understanding about each algorithm implemented in the GPU by using the CUDA profiler, where one can see the time of data transfer between GPU and CPU, achieved GPU occupancy, and so forth. Also, the acquisition and the image analysis with different image resolutions are shown in Fig. 13. This chart shows that the acquisition and the GPU analysis take comparable time for LSM. Table 6Processing time for single-exponential decay (unknown: τ, K).
Table 7Processing time for double-exponential decay (unknown: τF, K, fD).
Table 8Results from CUDA profiler for each algorithm.
Fig. 13Acquisition time (using the system reported in Ref. 18 as a reference) and image analysis time for LSM with different image resolutions.  3.2.ExperimentWe demonstrate the performances of the GPU-based BCMM on two-photon FLIM images of gold nanorods (GNRs) Cy5 labeled A375 cells. GNRs were conjugated with Cy5 labeled oligonucleotide through a procedure described elsewhere.54 The A375 cells were incubated with nanoprobes (GNR-Cy5) and fixed with paraformaldehyde. FLIM was performed using a confocal microscope (LSM 510, Carl Zeiss) equipped with a TCSPC module (SPC-830, Becker & Hickl GmbH). A femtosecond Ti:sapphire laser (Chameleon, Coherent) was tuned at 800 nm. The laser pulse has a repetition rate of 80 MHz and duration . Figure 14(a) shows the intensity– merged image obtained by BCMM, and it locates the (GNRs-Cy5)s by calculating their lifetimes (, in agreement with Chen et al.55) and . From the intensity image alone, it is impossible to identify the GNR sites. Combined with the average lifetime map, , in Fig. 14(b) and the map in Fig. 14(c), the lifetime histogram of at the GNR sites can be obtained to observe the energy transfer between Cy5 and GNRs, which offers a good indicator to study the hybridization of nanoprobes with targeting RNA in cells.56 Fig. 14(a) Intensity– merged image showing and the locations of the gold nanorods (GNRs). (b) Image of , (c) image, and (d) histogram at the GNR sites.  Table 9 compares the CPU and GPU parallel processing speed based on the experimental data when using the BCMM algorithm. These results further verify the power of the proposed GPU-FLIM tool. Table 9Experiment results with CPU-OpenMP and GPU.
4.DiscussionIn this study, the implementation and processing capabilities of a GPU-FLIM tool have been discussed and compared to traditional CPU-OpenMP based parallel analysis. We have also proposed some not unconventional but very important optimizations for GPU-based FLIM analysis. FLIM analysis is well suited for GPU acceleration because it is highly parallelizable. Each pixel in an FLIM frame can be processed independently of any other pixel, and, depending on the details of the algorithm, there is a lot of room for parallelization even within the processing of an individual pixel. From our simulations and experimental results, we observe that traditional iterative algorithms show better precision and working range and therefore remain the gold standard. On the other hand, although simple algorithms generally do not generate results of similar precision, they are much faster; for example, IEM is times faster than LSM. On the other hand, the photon efficiency (for single-exponential decays) of IEM is slightly worse than LSM- or MLE-based algorithms. To achieve the same precision for IEM, one needs to collect 2.5-fold more photons,57 which offsets some of the speed advantage of IEM, albeit by no means all of it.26 The requirements of precision and speed will vary depending on the research application, and a comprehensive FLIM analysis tool containing both noniterative and iterative algorithms is hence desirable. With the developed GPU-FLIM tool, we are able to achieve up to 24-fold enhancement over traditional CPU-based solutions, which now enables real-time or even video-rate FLIM analysis for simple algorithms (more than 37 fps can be achieved for images). For the more precise iterative algorithms, smaller FLIM images can be analyzed in real time; for example, it takes 59 ms to generate a frame of a FLIM image with 128 time bins using LSM. However, we expect to achieve up to 10 fps for images (our tool is currently at about 3 fps) by optimizing the LSM algorithm and GPU implementation specifically for this image size in the near future. The acquisition of the fastest TCSPC FLIM systems is currently only for images. Therefore, the bottleneck still remains image acquisition; however, with rapid advances in image sensors and microscopy technologies, we believe that the acquisition rate will be further enhanced in the near future. As mentioned above, lifetime estimations are parallelizable across all pixels (i.e., each pixel is independent), typically in a array. However, GPU analysis is not -fold faster than CPU parallel computing. There are two major limitations to the achieved GPU speedup: limitations of GPU hardware and limitations of the parallelization of FLIM algorithms. With respect to the former, although processing for each pixel is assigned into a separate thread (for noniterative algorithms) or block (for iterative algorithms), these do not mean that every pixel can be processed simultaneously because each GPU has limited resources (e.g., cores, memory). The exact number of pixels that can be launched in parallel varies with different GPU hardware and algorithm details, and they are at most and , respectively, for the GPU used here. The remaining pixels are processed when the first batch has completed and the GPU resources become available again. Another hardware limitation to GPU acceleration is that a single core of a GPU is not as powerful as a CPU core. We can easily find that runtime kernels of noniterative and iterative algorithms have different configurations, that is, each pixel is processed in a single thread for noniterative algorithms, in contrast to a block of threads for iterative algorithms. This leads to the second consideration: speedups are also limited by the degree to which algorithms can be parallelized. None of the algorithms described above can be fully parallelized with respect to the time bins, which means GPU resources cannot be fully occupied during the entire process of lifetime estimation. This leads to less than linear speedups as a function of the number of threads used. For noniterative algorithms, since the computations for each pixel need less hardware resources, this configuration allows a large number of pixels to be launched simultaneously. For iterative algorithms, one could also consider the same solution where each thread on the GPU processes an entire pixel instead of sharing this work in a block of threads with one thread per time bin as was done here. This would be more fully parallelizable, but it is unlikely to lead to further speedups because such a scheme would quickly conflict with the small amounts of registers and shared memory that are available on GPU chips. Between the two types of limitations, it is certainly the hardware capabilities that are more constraining at the moment. However, the development of GPU hardware continues with impressive advancements in short time scales, so that it is guaranteed that in the future GPUs will be able to boost FLIM analysis even further without a need for redevelopment of the parallelization strategy. Due to their large, unused potential, we will continue to explore the use of GPU acceleration and the parallelization of existing algorithms. In addition, we will begin to develop GPU-friendly algorithms. Once we have established real-time, wide-range, and high-precision FLIM analysis, we will implement an entire FLIM system, including both high-speed acquisition and high-performance FLIM analysis, to be used in the biological sciences, chemistry, medical research, and so forth. 5.ConclusionFLIM has recently gained attention as a powerful technique in biomedical imaging and clinical diagnosis applications, and there is an increasing demand for high-speed FLIM systems. In this article, we have proposed a flexible and reliable processing strategy for FLIM analysis using GPU acceleration, which can replace CPU-only solutions, allowing considerable speed improvements without loss of quality. The presented high-speed analysis tool has been implemented with some typical but important GPU code optimizations, tailored to the specific research area of fast, parallel lifetime analysis. The performance of the tool has been verified with synthesized and experimental data, demonstrating substantial potential for GPU acceleration in rapid FLIM analysis. AcknowledgmentsThe authors would like to thank the China Scholarship Council, NVIDIA, and the Royal Society (RG140915) for supporting this work. The authors would also like to acknowledge the Biotechnology and Biological Sciences Research Council (BBSRC grant: BB/K013416/1), the Engineering and Physical Sciences Research Council (EPSRC grant: EP/J019690/1), and the technical support from G. Wei and J. Sutter. ReferencesL. C. Chen et al.,
“Fluorescence lifetime imaging microscopy for quantitative biological imaging,”
Digital Microscopy, 457
–488 4th ed.Academic Press, Waltham, Massachusetts
(2013). Google Scholar
M. Nobis et al.,
“Intravital FLIM-FRET imaging reveals dasatinib-induced spatial control of SRC in pancreatic cancer,”
Cancer Res., 73
(15), 4674
–4686
(2013). http://dx.doi.org/10.1158/0008-5472.CAN-12-4545 CNREA8 0008-5472 Google Scholar
K. Okabe et al.,
“Intracellular temperature mapping with a fluorescent polymeric thermometer and fluorescence lifetime imaging microscopy,”
Nat. Commun., 3 705
(2012). http://dx.doi.org/10.1038/ncomms1714 NCAOBW 2041-1723 Google Scholar
M. A. Yaseen et al.,
“In vivo imaging of cerebral energy metabolism with two-photon fluorescence lifetime microscopy of NADH,”
Biomed. Opt. Express, 4
(2), 307
–321
(2013). http://dx.doi.org/10.1364/BOE.4.000307 BOEICL 2156-7085 Google Scholar
J.-D. J. Han et al.,
“Evidence for dynamically organized modularity in the yeast protein–protein interaction network,”
Nature, 430
(6995), 88
–93
(2004). http://dx.doi.org/10.1038/nature02555 Google Scholar
A. Miyawaki et al.,
“Dynamic and quantitative Ca2+ measurements using improved cameleons,”
Proc. Natl. Acad. Sci., 96
(5), 2135
–2140
(1999). http://dx.doi.org/10.1073/pnas.96.5.2135 Google Scholar
A. Agronskaia, L. Tertoolen and H. Gerritsen,
“High frame rate fluorescence lifetime imaging,”
J. Phys. D: Appl. Phys., 36
(14), 1655
–1662
(2003). http://dx.doi.org/10.1088/0022-3727/36/14/301 Google Scholar
M. Zhao, Y. Li and L. Peng,
“FPGA-based multi-channel fluorescence lifetime analysis of Fourier multiplexed frequency-sweeping lifetime imaging,”
Opt. Express, 22
(19), 23073
–23085
(2014). http://dx.doi.org/10.1364/OE.22.023073 OPEXFF 1094-4087 Google Scholar
Q. Zhao et al.,
“Modulated electron-multiplied fluorescence lifetime imaging microscope: all-solid-state camera for fluorescence lifetime imaging,”
J. Biomed. Opt., 17
(12), 126020
(2012). http://dx.doi.org/10.1117/1.JBO.17.12.126020 JBOPFO 1083-3668 Google Scholar
G. I. Redford and R. M. Clegg,
“Polar plot representation for frequency-domain analysis of fluorescence lifetimes,”
J. Fluoresc., 15
(5), 805
–815
(2005). http://dx.doi.org/10.1007/s10895-005-2990-8 JOFLEN 1053-0509 Google Scholar
H. Chen and E. Gratton,
“A practical implementation of multifrequency widefield frequency-domain fluorescence lifetime imaging microscopy,”
Microsc. Res. Tech., 76
(3), 282
–289
(2013). http://dx.doi.org/10.1002/jemt.22165 MRTEEO 1059-910X Google Scholar
R. A. Colyer, C. Lee and E. Gratton,
“A novel fluorescence lifetime imaging system that optimizes photon efficiency,”
Microsc. Res. Tech., 71
(3), 201
–213
(2008). http://dx.doi.org/10.1002/jemt.20540 MRTEEO 1059-910X Google Scholar
D. M. Grant et al.,
“High speed optically sectioned fluorescence lifetime imaging permits study of live cell signaling events,”
Opt. Express, 15
(24), 15656
–15673
(2007). http://dx.doi.org/10.1364/OE.15.015656 OPEXFF 1094-4087 Google Scholar
W. Becker,
“Fluorescence lifetime imaging—techniques and applications,”
J. Microsc., 247
(2), 119
–136
(2012). http://dx.doi.org/10.1111/j.1365-2818.2012.03618.x JMICAR 0022-2720 Google Scholar
L. Turgeman and D. Fixler,
“Photon efficiency optimization in time-correlated single photon counting technique for fluorescence lifetime imaging systems,”
IEEE Trans. Biomed. Eng., 60
(6), 1571
–1579
(2013). http://dx.doi.org/10.1109/TBME.2013.2238671 IEBEAX 0018-9294 Google Scholar
S. P. Poland et al.,
“A high speed multifocal multiphoton fluorescence lifetime imaging microscope for live-cell FRET imaging,”
Biomed. Opt. Express, 6
(2), 277
–296
(2015). http://dx.doi.org/10.1364/BOE.6.000277 BOEICL 2156-7085 Google Scholar
S. Kumar et al.,
“Multifocal multiphoton excitation and time correlated single photon counting detection for 3-D fluorescence lifetime imaging,”
Opt. Express, 15
(20), 12548
–12561
(2007). http://dx.doi.org/10.1364/OE.15.012548 OPEXFF 1094-4087 Google Scholar
J. L. Rinnenthal et al.,
“Parallelized TCSPC for dynamic intravital fluorescence lifetime imaging: quantifying neuronal dysfunction in neuroinflammation,”
PLoS One, 8
(4), e60100
(2013). http://dx.doi.org/10.1371/journal.pone.0060100 POLNCL 1932-6203 Google Scholar
S. P. Poland et al.,
“A high speed multifocal multiphoton fluorescence lifetime imaging microscope for live-cell FRET imaging,”
Biomed. Opt. Express, 6
(2), 277
–296
(2015). http://dx.doi.org/10.1364/BOE.6.000277 BOEICL 2156-7085 Google Scholar
C. Veerappan et al.,
“A single-photon image sensor with on-pixel 55 ps 10b time-to-digital converter,”
in IEEE Int. Solid-State Circuits Conf.,
312
–314
(2011). Google Scholar
R. M. Field, S. Realov and K. L. Shepard,
“A 100 fps, time-correlated single-photon-counting-based fluorescence-lifetime imager in 130 nm CMOS,”
IEEE J. Solid-State Circuits, 49
(4), 867
–880
(2014). http://dx.doi.org/10.1109/JSSC.2013.2293777 Google Scholar
D. Tyndall et al.,
“A high-throughput time-resolved mini-silicon photomultiplier with embedded fluorescence lifetime estimation in 0.13 μm CMOS,”
IEEE Trans. Biomed. Circuits Syst., 6
(6), 562
–570
(2012). http://dx.doi.org/10.1109/TBCAS.2012.2222639 Google Scholar
D. D. U. Li et al.,
“Video-rate fluorescence lifetime imaging camera with CMOS single-photon avalanche diode arrays and high-speed imaging algorithm,”
J. Biomed. Opt., 16
(9), 096012
(2011). http://dx.doi.org/10.1117/1.3625288 JBOPFO 1083-3668 Google Scholar
J. A. Jo et al.,
“Novel ultra-fast deconvolution method for fluorescence lifetime imaging microscopy based on the Laguerre expansion technique,”
in Proc. of the 26th Annual Int. Conf. of the IEEE Engineering in Medicine and Biology Society,
1271
–1274
(2004). Google Scholar
S. P. Chan et al.,
“Optimized gating scheme for rapid lifetime determinations of single-exponential luminescence lifetimes,”
Anal. Chem., 73
(18), 4486
–4490
(2001). http://dx.doi.org/10.1021/ac0102361 ANCHAM 0003-2700 Google Scholar
D. U. Li et al.,
“Real-time fluorescence lifetime imaging system with a 0.13 microm CMOS low dark-count single-photon avalanche diode array,”
Opt. Express, 18
(10), 10257
–10269
(2010). http://dx.doi.org/10.1364/OE.18.010257 OPEXFF 1094-4087 Google Scholar
Y. J. Won, W. T. Han and D. Y. Kim,
“Precision and accuracy of the analog mean-delay method for high-speed fluorescence lifetime measurement,”
J. Opt. Soc. Am. A, 28
(10), 2026
–2032
(2011). http://dx.doi.org/10.1364/JOSAA.28.002026 Google Scholar
M. A. Digman et al.,
“The phasor approach to fluorescence lifetime imaging analysis,”
Biophys. J., 94
(2), L14
–L16
(2008). http://dx.doi.org/10.1529/biophysj.107.120154 BIOJAU 0006-3495 Google Scholar
A. Leray et al.,
“Spatio-temporal quantification of FRET in living cells by fast time-domain FLIM: a comparative study of non-fitting methods,”
PLoS One, 8
(7), e69335
(2013). http://dx.doi.org/10.1371/journal.pone.0069335 POLNCL 1932-6203 Google Scholar
I. Gregor et al.,
“Fast algorithms for the analysis of spectral FLIM data,”
Proc. SPIE, 7903 790330
(2011). http://dx.doi.org/10.1117/12.873386 PSISDG 0277-786X Google Scholar
D. U. Li, H. Yu and Y. Chen,
“Fast bi-exponential fluorescence lifetime imaging analysis methods,”
Opt. Lett., 40
(3), 336
–339
(2015). http://dx.doi.org/10.1364/OL.40.000336 OPLEDP 0146-9592 Google Scholar
M. Elangovan, R. N. Day and A. Periasamy,
“Nanosecond fluorescence resonance energy transfer-fluorescence lifetime imaging microscopy to localize the protein interactions in a single living cell,”
J. Microsc., 205 3
–14
(2002). http://dx.doi.org/10.1046/j.0022-2720.2001.00984.x Google Scholar
P. Hall and B. Selinger,
“Better estimates of exponential decay parameters,”
J. Phys. Chem., 85
(20), 2941
–2946
(1981). http://dx.doi.org/10.1021/j150620a019 JPCHAX 0022-3654 Google Scholar
A. A. Istratov and O. F. Vyvenko,
“Exponential analysis in physical phenomena,”
Rev. Sci. Instrum., 70
(2), 1233
–1257
(1999). http://dx.doi.org/10.1063/1.1149581 RSINAK 0034-6748 Google Scholar
P. R. Barber et al.,
“Global and pixel kinetic data analysis for FRET detection by multi-photon time-domain FLIM,”
Proc. SPIE, 5700 171
–181
(2005). http://dx.doi.org/10.1117/12.590510 PSISDG 0277-786X Google Scholar
S. C. Warren et al.,
“Rapid global fitting of large fluorescence lifetime imaging microscopy datasets,”
PLoS One, 8
(8), e70687
(2013). http://dx.doi.org/10.1371/journal.pone.0070687 POLNCL 1932-6203 Google Scholar
P. J. Verveer, A. Squire and P. I. Bastiaens,
“Global analysis of fluorescence lifetime imaging microscopy data,”
Biophys. J., 78
(4), 2127
–2137
(2000). http://dx.doi.org/10.1016/S0006-3495(00)76759-2 BIOJAU 0006-3495 Google Scholar
D. D. U. Li et al.,
“Time-domain fluorescence lifetime imaging techniques suitable for solid-state imaging sensor arrays,”
Sensors, 12
(5), 5650
–5669
(2012). http://dx.doi.org/10.3390/s120505650 SNSRES 0746-9462 Google Scholar
M. Broxton et al.,
“Wave optics theory and 3-D deconvolution for the light field microscope,”
Opt. Express, 21
(21), 25418
–25439
(2013). http://dx.doi.org/10.1364/OE.21.025418 OPEXFF 1094-4087 Google Scholar
Y. Jian, K. Wong and M. V. Sarunic,
“Graphics processing unit accelerated optical coherence tomography processing at megahertz axial scan rate and high resolution video rate volumetric rendering,”
J. Biomed. Opt., 18
(2), 026002
(2013). http://dx.doi.org/10.1117/1.JBO.18.2.026002 JBOPFO 1083-3668 Google Scholar
G. Yan et al.,
“Fast cone-beam CT image reconstruction using GPU hardware,”
J. X-ray Sci. Technol., 16
(4), 225
–234
(2008). JXSTE5 0895-3996 Google Scholar
X. L. Dean-Ben, A. Ozbek and D. Razansky,
“Volumetric real-time tracking of peripheral human vasculature with GPU-accelerated three-dimensional optoacoustic tomography,”
IEEE Trans. Med. Imaging, 32
(11), 2050
–2055
(2013). http://dx.doi.org/10.1109/TMI.2013.2272079 ITMID4 0278-0062 Google Scholar
R. Zanella et al.,
“Towards real-time image deconvolution: application to confocal and STED microscopy,”
Sci. Rep., 3 2523
(2013). http://dx.doi.org/10.1038/srep02523 SRCEC3 2045-2322 Google Scholar
M. Ploschner and T. Cizmar,
“Compact multimode fiber beam-shaping system based on GPU accelerated digital holography,”
Opt. Lett., 40
(2), 197
–200
(2015). http://dx.doi.org/10.1364/OL.40.000197 OPLEDP 0146-9592 Google Scholar
“Parallel Programming and Computing Platform CUDA,”
2015). http://www.nvidia.com/object/cuda_home_new.html Google Scholar
N. Wilt, The CUDA Handbook: A Comprehensive Guide to GPU Programming, Addison-Wesley, Boston, Mass., London
(2013). Google Scholar
N. Corporation, CUDA C Programming Guide, NVIDIA, Santa Clara, California
(2014). Google Scholar
A. Neic et al.,
“Accelerating cardiac bidomain simulations using graphics processing units,”
IEEE Trans. Biomed. Eng., 59
(8), 2281
–2290
(2012). http://dx.doi.org/10.1109/TBME.2012.2202661 Google Scholar
J. A. Goodman, D. Kaeli and D. Schaa,
“Accelerating an imaging spectroscopy algorithm for submerged marine environments using graphics processing units,”
IEEE J. Sel. Topics Appl. Earth Obs. Remote Sens., 4
(3), 669
–676
(2011). http://dx.doi.org/10.1109/JSTARS.2011.2108269 Google Scholar
J. Sanders and E. Kandrot, CUDA by Example: An Introduction to General-Purpose GPU Programming, Addison-Wesley, Upper Saddle River; London
(2011). Google Scholar
M. Harris,
“Optimizing parallel reduction in CUDA,”
NVIDIA Develop.Technol., 2
(4), 1
–38
(2007). Google Scholar
NVIDIA, CUDA C Best Practices Guide, NVIDIA Corporation, Santa Clara, California
(2014). Google Scholar
D. Kirk and W. M. Hwu, Programming Massively Parallel Processors Hands-on With CUDA, Morgan Kaufmann Publishers, Burlington, MA
(2010). Google Scholar
Y. Zhang et al.,
“FD 178: surface plasmon enhanced energy transfer between gold nanorods and fluorophores: application to endosytosis study and RNA detection,”
Faraday Discuss., 178 383
–394
(2014). http://dx.doi.org/10.1039/C4FD00199K Google Scholar
Y. Chen et al.,
“Creation and luminescence of size-selected gold nanorods,”
Nanoscale, 4
(16), 5017
–5022
(2012). http://dx.doi.org/10.1039/c2nr30324h NANOHL 2040-3364 Google Scholar
Y. Zhang, D. J. Birch and Y. Chen,
“Energy transfer between DAPI and gold nanoparticles under two-photon excitation,”
Appl. Phys. Lett., 99 103701
(2011). http://dx.doi.org/10.1063/1.3633066 APPLAB 0003-6951 Google Scholar
D. U. Li et al.,
“On-chip, time-correlated, fluorescence lifetime extraction algorithms and error analysis,”
J. Opt. Soc. Am. A, 25
(5), 1190
–1198
(2008). http://dx.doi.org/10.1364/JOSAA.25.001190 Google Scholar
BiographyGang Wu is a PhD student at the University of Sussex and a visiting scholar at the University of Strathclyde. He received his MS degree in system analysis and integration from Zhejiang University in 2013. His current research interests include fluorescence lifetime imaging microscopy (FLIM) analysis, fluorescence-based sensing systems, graphic processing unit (GPU) computing, and biophotonics. Thomas Nowotny is a professor in informatics at the School of Engineering and Informatics, University of Sussex, United Kingdom. He has a track record in modeling insect olfactories, hybrid computer/brain systems, GPU computing, and artificial neural networks. He has been a pioneer in GPU computing for neural network using NVIDIA® CUDA™ and developed the code-generation-based framework GeNN currently used in the Green Brain project (EPSRC) and in the Task 11.3.6 in the EU Human Brain Project. Yu Chen is a senior lecturer in nanometrology at the Department of Physics, University of Strathclyde, United Kingdom. Her recent research focuses on fluorescent gold nanoparticles and surface plasmon enhanced effects, including two-photon luminescence, energy transfer, and SERRS from noble metal nanoparticles, arrays, and porous media, with strong links to biomedical imaging and sensing, as well as nanoparticle–cell interaction and cytotoxicity. David Day-Uei Li is a senior lecturer in biophotonics at the Strathclyde Institute of Pharmacy & Biomedical Sciences, University of Strathclyde, United Kingdom. He has research projects in developing CMOS FLIM or spectroscopy systems, FPGA/GPU computing, tomography, FLIM imaging analysis, and mixed-signal circuits. His research exploits advanced sensor technologies to reveal low-light but fast biological phenomena. He has published more than 60 journal and conference papers and holds 12 patents. |